
摘要: 最完整的微服务化示例,从业务场景入手,讲述微服务化架构设计、容器化、集群部署、弹性伸缩
本文转载自 微服务 开源项目 Apache ServiceComb (incubating) 官网博客:
http://servicecomb.incubator.apache.org/cn/docs/linuxcon-workshop-demo/
http://servicecomb.incubator.apache.org/cn/docs/company-on-kubernetes/
http://servicecomb.incubator.apache.org/cn/docs/autoscale-on-company/
微服务架构作为新兴领域的架构模式,已步入产品化形态,与容器化、集群等一起成为了当下热点。而微服务、Docker、kubernetes 之间的关系,究竟这三者之间是什么样的关系,分别能在微服务领域发挥什么作用,却常给入门的读者和用户带来些许迷茫感。
本文使用一个简单的普适性的 微服务 示例,从 业务场景入手,到微服务架构设计、实现、容器化、集群部署、压测、弹性伸缩、资源控制,端到端以最直白的方式演示了这三者的关系,会给读者带来不一样的真切的理念体验和感受,增强对系列概念的理解。
普适性微服务化示例
为了读者能更容易了解ServiceComb微服务框架的功能以及如何用其快速开发微服务,所以提供大家耳熟能详的例子,降低学习曲线的同时,增加趣味性,加深理解。
本文中假设我们成立了一家科研公司,处理复杂的数学运算,以及尖端生物科技研究,并为用户提供如下服务:
黄金分割数列计算
蜜蜂繁殖规律 (计算每只雄蜂/雌蜂的祖先数量)
但是我们如何将公司的这些强大运算能力提供给我们的消费者呢?
首先我们通过认证服务保障公司的计算资源没有被滥用, 同时我们对外提供Rest服务让用户来进行访问。 下面的视频展示具体的服务验证调用的情况。
业务场景
让我们先对业务场景进行总结分析
为了公司持续发展,我们需要对用户消费的运算能力收费,所以我们聘用了门卫认证用户,避免不法分子混入
为了提供足够的黄金分割数量运算能力,我们需要雇佣相应的技工
为了持续研究蜜蜂繁殖规律,公司建立了自己的蜂场,需要相应的养蜂人进行管理研究
为了平衡技工、养蜂人、和门卫的工作量和时间,我们建立了告示栏机制,让当前有闲暇的人员发布自己的联系方式,以便我们能及时联系技能匹配的人员以服务到来的用户
因为运算能力成本高昂,我们将运算项目进行了归档,以便未来有相同请求时,我们能直接查询项目归档,节省公司运算成本
面对上述复杂的场景,我们又聘用了部门经理来管理公司成员和设施
最后,当公司日益壮大,用户数量暴涨时,我们还需要招聘更多技工、养蜂人、和门卫,所以增加了人力资源部门
公司结构 (系统架构)
到现在业务场景已经比较清晰,我们把上述职务部门和设施画成公司组织结构图。
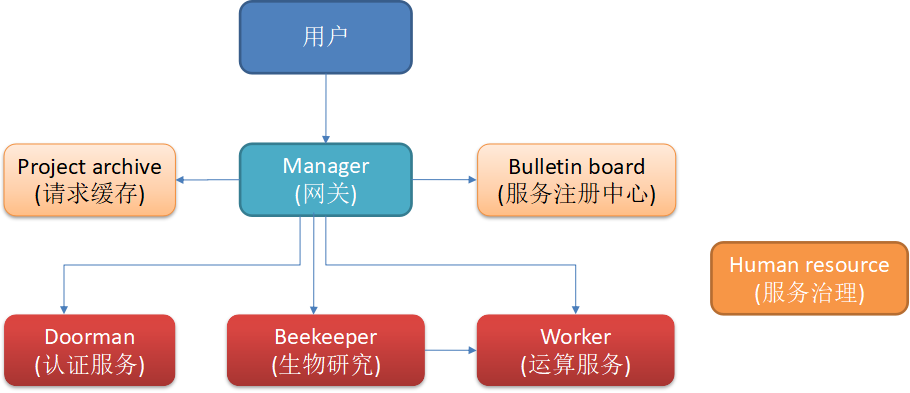
现在公司组织结构已经完整,让我们着手搭建相应部门。
技工 (Worker)
因为技工最为简单,对其他部门人员依赖最少,我们首先搭建这个部门。
黄金分割运算服务
技工的主要工作时提供黄金分割数列计算服务,当用户需要知道第n个黄金分割数时,技工以最快的速度计算出数值并返回给用户。 我们可以把这个工作简化为如下数学方程:
value = fibo(n)
在暂时不考虑性能的情况下,我们可以迅速实现黄金分割数列的计算。
interface FibonacciService { long term(int n);
}@Serviceclass FibonacciServiceImpl implements FibonacciService { @Override
public long term(int n) { if (n == 0) { return 0;
} else if (n == 1) { return 1;
} return term(n - 1) + term(n - 2);
}
}
技工服务端点
黄金分割数量运算已经实现,现在我们需要将服务提供给用户,首先我们定义端点接口:
public interface FibonacciEndpoint { long term(int n);
}
引入 ServiceComb 依赖:
<dependency> <groupId>org.apache.servicecomb</groupId> <artifactId>spring-boot-starter-provider</artifactId> </dependency>
接下来我们同时暴露黄金分割运算服务的Restful和RPC端点:
@RestSchema(schemaId = "fibonacciRestEndpoint")@RequestMapping("/fibonacci")@Controllerpublic class FibonacciRestEndpoint implements FibonacciEndpoint { private final FibonacciService fibonacciService; @Autowired
FibonacciRestEndpoint(FibonacciService fibonacciService) { this.fibonacciService = fibonacciService;
} @Override
@RequestMapping(value = "/term", method = RequestMethod.GET) @ResponseBody
public long term(int n) { return fibonacciService.term(n);
}
}
@RpcSchema(schemaId = "fibonacciRpcEndpoint")public class FibonacciRpcEndpoint implements FibonacciEndpoint { private final FibonacciService fibonacciService; @Autowired
public FibonacciRpcEndpoint(FibonacciService fibonacciService) { this.fibonacciService = fibonacciService;
} @Override
public long term(int n) { return fibonacciService.term(n);
}
}
这里用 @RestSchema 和 @RpcSchema 注释两个端点后,ServiceComb 会自动生成对应的服务端点契约,根据如下microsevice.yaml 配置端点端口,并将契约和服务一起注册到Service Center:
# all interconnected microservices must belong to an application wth the same IDAPPLICATION_ID: companyservice_description:# name of the declaring microservice name: worker version: 0.0.1# service center addresscse: service: registry: address: http://sc.servicecomb.io:30100 highway: address: 0.0.0.0:7070 rest: address: 0.0.0.0:8080
最后,提供技工服务应用启动入口,并加上 @EnableServiceComb 注释启用 ServiceComb :
@SpringBootApplication@EnableServiceCombpublic class WorkerApplication { public static void main(String[] args) {
SpringApplication.run(WorkerApplication.class, args);
}
}
告示栏 (Bulletin Board)
告示栏提供为门卫、技工和养蜂人注册联系方式的设施,同时经理和养蜂人可通过此设施查询注册方的联系方式,以方便匹配能力的提供和消费。
Service Center 提供契约和服务注册、发现功能,而且校验服务提供方和消费方的契约是否匹配,我们可以下载编译好的版本直接运行。
养蜂人 (Beekeeper)
养蜂人研究蜜蜂繁殖规律,计算每只蜜蜂 (雄蜂/雌蜂) 的祖先数量。因为蜜蜂繁殖规律和黄金分割数列相关,所以养蜂人同时消费技工提供的计算服务。
研究表明,雄蜂(Drone)由未受精卵孵化而生,只有母亲;而雌蜂(Queen)由受精卵孵化而生,既有母又有父。
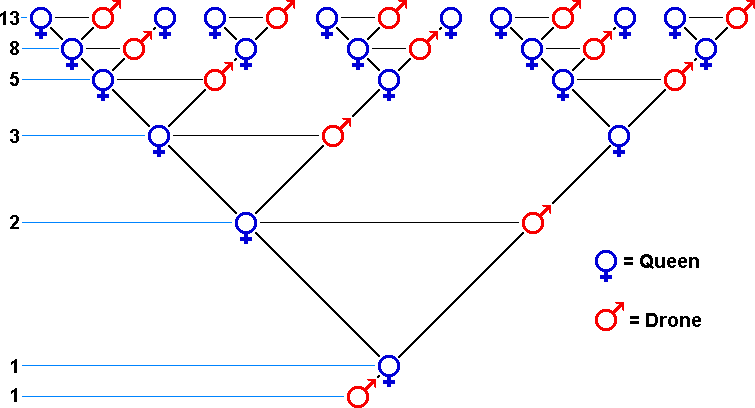 Credit: Dave Cushman’s website
Credit: Dave Cushman’s website
参考上图,蜜蜂的某一代祖先数量符合黄金分割数列的模型,由此我们可以很快实现服务功能。
蜜蜂繁殖规律研究服务
首先我们定义黄金数列运算接口:
public interface FibonacciCalculator { long term(int n);
}
接下来定义并实现蜜蜂繁殖规律研究服务:
interface BeekeeperService { long ancestorsOfDroneAt(int generation); long ancestorsOfQueenAt(int generation);
}class BeekeeperServiceImpl implements BeekeeperService { private final FibonacciCalculator fibonacciCalculator;
BeekeeperServiceImpl(FibonacciCalculator fibonacciCalculator) { this.fibonacciCalculator = fibonacciCalculator;
} @Override
public long ancestorsOfDroneAt(int generation) { if (generation <= 0) { return 0;
} return fibonacciCalculator.term(generation + 1);
} @Override
public long ancestorsOfQueenAt(int generation) { if (generation <= 0) { return 0;
} return fibonacciCalculator.term(generation + 2);
}
}
这里我们用到之前定义的 FibonacciCalculator 接口,并希望通过这个接口远程调用技工服务端点。@RpcReference 注释能帮助我们自动从Service Center中获取 microserviceName = "worker", schemaId = "fibonacciRpcEndpoint" , 即服务名为 worker 已经schema ID为 fibonacciRpcEndpoint的端点:
@Configurationclass BeekeeperConfig { @RpcReference(microserviceName = "worker", schemaId = "fibonacciRpcEndpoint") private FibonacciCalculator fibonacciCalculator; @Bean
BeekeeperService beekeeperService() { return new BeekeeperServiceImpl(fibonacciCalculator);
}
}
我们在技工一节已定义好对应的服务名和schema ID端点,通过上面的配置,ServiceComb 会自动将远程技工服务 实例和 FibonacciCalculator 绑定在一起。
养蜂人服务端点
与上一节技工服务相似,我们在这里也需要提供养蜂人服务端点,让用户可以进行调用:
@RestSchema(schemaId = "beekeeperRestEndpoint")@RequestMapping("/rest")@Controllerpublic class BeekeeperController { private static final Logger logger = LoggerFactory.getLogger(BeekeeperController.class); private final BeekeeperService beekeeperService; @Autowired
BeekeeperController(BeekeeperService beekeeperService) { this.beekeeperService = beekeeperService;
} @RequestMapping(value = "/drone/ancestors/{generation}", method = GET, produces = APPLICATION_JSON_UTF8_VALUE)
@ResponseBody
public Ancestor ancestorsOfDrone(@PathVariable int generation) {
logger.info( "Received request to find the number of ancestors of drone at generation {}",
generation); return new Ancestor(beekeeperService.ancestorsOfDroneAt(generation));
} @RequestMapping(value = "/queen/ancestors/{generation}", method = GET, produces = APPLICATION_JSON_UTF8_VALUE)
@ResponseBody
public Ancestor ancestorsOfQueen(@PathVariable int generation) {
logger.info( "Received request to find the number of ancestors of queen at generation {}",
generation); return new Ancestor(beekeeperService.ancestorsOfQueenAt(generation));
}
}class Ancestor { private long ancestors;
Ancestor() {
}
Ancestor(long ancestors) { this.ancestors = ancestors;
} public long getAncestors() { return ancestors;
}
}
因为养蜂人需要消费技工提供的服务,所以其 microservice.yaml 配置稍有不同:
# all interconnected microservices must belong to an application wth the same IDAPPLICATION_ID: companyservice_description:# name of the declaring microservice name: beekeeper version: 0.0.1cse: service: registry: address: http://sc.servicecomb.io:30100 rest: address: 0.0.0.0:8090 handler: chain: Consumer: default: bizkeeper-consumer,loadbalance references:# this one below must refer to the microservice name it communicates with worker: version-rule: 0.0.1
这里我们需要定义 cse.references.worker.version-rule ,让配置名称中指向技工服务名 worker ,并匹配其版本号。
最后定义养蜂人服务应用入口:
@SpringBootApplication@EnableServiceCombpublic class BeekeeperApplication { public static void main(String[] args) {
SpringApplication.run(BeekeeperApplication.class, args);
}
}
门卫 (Doorman)
门卫为公司提供安全保障,屏蔽非合法用户,防止其骗取免费服务,甚至伤害技工和养蜂人。
门卫认证服务
认证功能我们采用JSON Web Token (JWT)的机制,具体实现超出了这篇文章的范围, 细节大家可以查看github上workshop的 doorman 模块代码。
认证服务的接口如下,authenticate 方法根据用户名和密码查询确认用户存在,并返回对应JWT token。用户登录后的每次 请求都需要带上返回的JWT token,而 validate 方法将验证token以确认其有效。
public interface AuthenticationService { String authenticate(String username, String password); String validate(String token);
}
门卫认证服务端点
与前两节的Rest服务端点相似,我们加上 @RestSchema 注释,以便 ServiceComb 自动配置端点、生成契约并注册服务。
@RestSchema(schemaId = "authenticationRestEndpoint")@Controller@RequestMapping("/rest")public class AuthenticationController { private static final Logger logger = LoggerFactory.getLogger(AuthenticationController.class);
static final String USERNAME = "username";
static final String PASSWORD = "password";
static final String TOKEN = "token"; private final AuthenticationService authenticationService; @Autowired
AuthenticationController(AuthenticationService authenticationService) { this.authenticationService = authenticationService;
} @RequestMapping(value = "/login", method = POST, produces = TEXT_PLAIN_VALUE)
public ResponseEntity<String> login( @RequestParam(USERNAME) String username, @RequestParam(PASSWORD) String password) {
logger.info("Received login request from user {}", username);
String token = authenticationService.authenticate(username, password);
HttpHeaders headers = new HttpHeaders();
headers.add(AUTHORIZATION, TOKEN_PREFIX + token);
logger.info("Authenticated user {} successfully", username); return new ResponseEntity<>("Welcome, " + username, headers, OK);
} @RequestMapping(value = "/validate", method = POST, consumes = APPLICATION_JSON_UTF8_VALUE, produces = TEXT_PLAIN_VALUE)
@ResponseBody
public String validate(@RequestBody Token token) {
logger.info("Received validation request of token {}", token); return authenticationService.validate(token.getToken());
}
}class Token { private String token;
Token() {
}
Token(String token) { this.token = token;
} public String getToken() { return token;
} @Override
public String toString() { return "Token{" + "token='" + token + '\'' + '}';
}
}
同样,我们需要提供服务应用启动入口以及 microservice.yaml:
@SpringBootApplication@EnableServiceCombpublic class DoormanApplication { public static void main(String[] args) {
SpringApplication.run(DoormanApplication.class, args);
}
}
# all interconnected microservices must belong to an application wth the same IDAPPLICATION_ID: companyservice_description:# name of the declaring microservice name: doorman version: 0.0.1cse: service: registry: address: http://sc.servicecomb.io:30100 rest: address: 0.0.0.0:9090
经理 (Manager)
为了管理所有人员和设施,经理作为用户唯一接口人,主要功能有:
联系门卫认证用户,保护技工和养蜂人,以免非法用户骗取服务并逃避服务费用
联系能力相符的技工和养蜂人,平衡工作量,避免单个人员工作超载
管理项目归档,避免重复工作,保证公司收益最大化
由于经理责任重大,我们选取了业界有名的Netflix Zuul作为候选人并加以培训, 提升其能力,以保证其能胜任该职位。
首先我们引入依赖:
<dependency> <groupId>org.apache.servicecomb</groupId> <artifactId>spring-boot-starter-discovery</artifactId> </dependency>
用户认证服务
当用户发送非登录请求时,我们首先需要验证用户合法,在如下服务中,我们通过告示栏获取门卫联系方式, 然后发送用户token给门卫进行认证。
ServiceComb 提供了相应 RestTemplate 实现查询Service Center 中的服务注册信息,只需在地址中以如下格式包含被调用的服务名
cse://doorman/path/to/rest/endpoint
ServiceComb 将自动查询对应服务并发送请求到地址中的服务端点。
@Servicepublic class AuthenticationService { private static final Logger logger = LoggerFactory.getLogger(AuthenticationService.class); private static final String DOORMAN_ADDRESS = "cse://doorman"; private final RestTemplate restTemplate;
AuthenticationService() { this.restTemplate = RestTemplateBuilder.create(); this.restTemplate.setErrorHandler(new ResponseErrorHandler() { @Override
public boolean hasError(ClientHttpResponse clientHttpResponse) throws IOException { return false;
} @Override
public void handleError(ClientHttpResponse clientHttpResponse) throws IOException {
}
});
} @HystrixCommand(fallbackMethod = "timeout") public ResponseEntity<String> validate(String token) {
logger.info("Validating token {}", token);
ResponseEntity<String> responseEntity = restTemplate.postForEntity(
DOORMAN_ADDRESS + "/rest/validate",
validationRequest(token),
String.class
); if (!responseEntity.getStatusCode().is2xxSuccessful()) {
logger.warn("No such user found with token {}", token);
}
logger.info("Validated request of token {} to be user {}", token, responseEntity.getBody()); return responseEntity;
} private ResponseEntity<String> timeout(String token) {
logger.warn("Request to validate token {} timed out", token); return new ResponseEntity<>(REQUEST_TIMEOUT);
} private HttpEntity<Token> validationRequest(String token) {
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON_UTF8); return new HttpEntity<>(new Token(token), headers);
}
}
请求过滤
接下来我们提供 ZuulFilter 实现过滤用户请求,调用 authenticationService.validate(token) 认证用户token。 若用户合法则路由用户请求到对应服务,否则返回 403 forbidden。
@Componentclass AuthenticationAwareFilter extends ZuulFilter { private static final Logger logger = LoggerFactory.getLogger(AuthenticationAwareFilter.class); private static final String LOGIN_PATH = "/login"; private final AuthenticationService authenticationService; private final PathExtractor pathExtractor; @Autowired
AuthenticationAwareFilter(
AuthenticationService authenticationService,
PathExtractor pathExtractor) { this.authenticationService = authenticationService; this.pathExtractor = pathExtractor;
} @Override
public String filterType() { return "pre";
} @Override
public int filterOrder() { return 1;
} @Override
public boolean shouldFilter() {
String path = pathExtractor.path(RequestContext.getCurrentContext());
logger.info("Received request with query path: {}", path); return !path.endsWith(LOGIN_PATH);
} @Override
public Object run() {
filter(); return null;
} private void filter() {
RequestContext context = RequestContext.getCurrentContext(); if (doesNotContainToken(context)) {
logger.warn("No token found in request header");
rejectRequest(context);
} else {
String token = token(context);
ResponseEntity<String> responseEntity = authenticationService.validate(token); if (!responseEntity.getStatusCode().is2xxSuccessful()) {
logger.warn("Unauthorized token {} and request rejected", token);
rejectRequest(context);
} else {
logger.info("Token {} validated", token);
}
}
} private void rejectRequest(RequestContext context) {
context.setResponseStatusCode(SC_FORBIDDEN);
context.setSendZuulResponse(false);
} private boolean doesNotContainToken(RequestContext context) { return authorizationHeader(context) == null
|| !authorizationHeader(context).startsWith(TOKEN_PREFIX);
} private String token(RequestContext context) { return authorizationHeader(context).replace(TOKEN_PREFIX, "");
} private String authorizationHeader(RequestContext context) { return context.getRequest().getHeader(AUTHORIZATION);
}
}
最后提供服务应用入口:
@SpringBootApplication@EnableCircuitBreaker@EnableZuulProxy@EnableDiscoveryClient@EnableServiceCombpublic class ManagerApplication { public static void main(String[] args) {
SpringApplication.run(ManagerApplication.class, args);
}
}
application.yaml 中定义路由规则:
zuul: routes: doorman: serviceId: doorman sensitiveHeaders: worker: serviceId: worker beekeeper: serviceId: beekeeper# disable netflix eurkea since it's not used for service discoveryribbon: eureka: enabled: false
microservice.yaml 中定义服务中心地址:
APPLICATION_ID: companyservice_description: name: manager version: 0.0.1cse: service: registry: address: http://sc.servicecomb.io:30100
项目归档 (Project Archive)
经理在每次用户请求后将项目进行归档,如果将来有内容相同的请求到达,经理可以就近获取结果,不必再购买 技工和养蜂人提供的计算服务,节省公司开支。
对于归档功能的实现,我们采用了Spring Cache Abstraction,具体细节超出了这篇文章的范围,大家如果有兴趣可以 查看github上workshop的 manager 模块代码。
人力资源 (Human Resource)
人力资源从运维层面保证服务的可靠性,主要功能有
弹性伸缩,以保证用户请求量超过技工或养蜂人处理能力后,招聘更多技工或养蜂人加入项目;当请求量回落后,裁剪技工或养蜂人以节省公司开支
健康检查,以保证技工或养蜂人告病时,能有替补接手任务
滚动升级,以保证项目需要新技能时,能替换、培训技工或养蜂人,不中断接收用户请求
人力资源的功能需要云平台提供支持,在后续的文章中会跟大家介绍,我们如何在华为云上轻松实现这些功能。
微服务化小结
至此,我们用一个公司的组织结构作为例子,给大家介绍了微服务的完整架构,以及如何使用微服务框架 ServiceComb快速开发微服务,以及服务间互通、契约认证。
Workshop demo项目也包含大量完整易懂的测试 代码,以及使用docker集成微服务,模拟生存环境,同时应用Travis搭建持续集成环境,体现 DevOps在微服务开发中的实践。希望能对大家有所帮助。
容器化并集群部署
现在,github上已经提供了在kubernetes集群上一键式部署的功能。本文将着重讲解相应的yaml文件和服务间通信,这对于开发者基于Company 模型进行微服务开发并且部署到云上将会有所帮助。
一键部署
Run Company on Kubernetes Cluster 提供了详细的使用方法,读者只需通过以下3条指令,就可将company在kubernetes集群上部署起来,
git clone https://github.com/ServiceComb/ServiceComb-Company-WorkShop.gitcd ServiceComb-Company-WorkShop/kubernetes/bash start.sh
Yaml文件解读
以作者的实际环境为例:
root@zenlin:~/src/LinuxCon-Beijing-WorkShop/kubernetes# kubectl get pod -owide NAME READY STATUS RESTARTS AGE IP NODE company-beekeeper-3737555734-48sxf 1/1 Running 0 17s 10.244.2.49 zenlinnode2 company-bulletin-board-4113647782-th91w 1/1 Running 0 17s 10.244.1.53 zenlinnode1 company-doorman-3391375245-g0p8c 1/1 Running 0 17s 10.244.1.55 zenlinnode1 company-manager-454733969-0c1g8 1/1 Running 0 16s 10.244.2.50 zenlinnode2 company-worker-1085546725-x7zl4 1/1 Running 0 17s 10.244.1.54 zenlinnode1 zipkin-508217170-0khr3 1/1 Running 0 17s 10.244.2.48 zenlinnode2
可以看到,一共启动了6个pod,分别为,公司经理(company-manager)、门卫(company-doorman)、公告栏(company-bulletin-board)、技工(company-worker)、养蜂人(company-beekeeper)、调用链跟踪(zipkin),K8S集群分别为他们分配对应的集群IP。
root@zenlin:~/src/LinuxCon-Beijing-WorkShop/kubernetes# kubectl get svc -owide NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR company-bulletin-board 10.99.70.46 <none> 30100/TCP 12m io.kompose.service=company-bulletin-board company-manager 10.100.61.227 <nodes> 8083:30301/TCP 12m io.kompose.service=company-manager zipkin 10.104.92.198 <none> 9411/TCP 12m io.kompose.service=zipkin
仅启动了3个service,调用链跟踪(zipkin)、公告栏(company-bulletin-board)以及经理(company-manager),这是因为,调用链跟踪和公告栏需要在集群内被其他服务通过域名来调用,而经理需要作为对外作为网关,统一暴露服务端口。
查看company-bulletin-board-service.yaml文件,
apiVersion: v1 kind: Service metadata: creationTimestamp: null labels:
io.kompose.service: company-bulletin-board name: company-bulletin-board spec: ports:
- name: "30100"
port: 30100
targetPort: 30100
selector:
io.kompose.service: company-bulletin-board status: loadBalancer: {}
该文件定义了公告栏对应的service,给service定义了name、port和targetPort,这样通过kubectl expose创建的service会在集群内具备DNS能力,在其他服务刚启动还未注册到公告栏(服务注册发现中心)时,就是使用该能力来访问到公告栏并注册服务的。
对于label和selector的作用,在一个service启动多个pod的场景下将会非常有用,当某个pod崩溃时,服务的selector将会自动将死亡的pod从endpoints中移除,并且选择新的pod加入到endpoints中。
查看company-worker-deployment.yaml 文件,
apiVersion: extensions/v1beta1kind: Deploymentmetadata: creationTimestamp: null labels:
io.kompose.service: company-worker name: company-workerspec: replicas: 1 strategy: {} template:
metadata:
creationTimestamp: null
labels:
io.kompose.service: company-workerspec: containers: - env: - name: ARTIFACT_ID value: worker - name: JAVA_OPTS value: -Dcse.service.registry.address=http://company-bulletin-board:30100 -Dservicecomb.tracing.collector.adress=http://zipkin:9411 image: servicecomb/worker:0.0.1-SNAPSHOT name: company-worker ports: - containerPort: 7070 - containerPort: 8080 resources: {} restartPolicy: Alwaysstatus: {}
该yaml文件定义了副本数为1(replicas: 1)的pod,可以通过修改该副本数控制所需启动的pod的副本数量(当然也可以使用K8S的弹性伸缩能力去实现按需动态水平伸缩,弹性伸缩部分将在后面的博文中提供)。前面我们提到过company-bulletin-board具备了DNS的能力,故现在可以通过该Deployment中的env传递cse.service.registry.address的值给pod内的服务使用,如: -Dcse.service.registry.address=http://company-bulletin-board:30100,kube-dns将会自动解析该servicename。
对于kubernetes如何实现服务间通信,可以阅读connect-applications-service。
其他的deployment.yaml以及service.yaml都跟以上大同小异,唯一例外的是company-manager服务,我们可以看到在company-manager-service.yaml中看到定义了nodePort,这将使能company-manager对集群外部提供公网IP和服务端口,如下:
spec: ports: - name: "8083" port: 8083 targetPort: 8080 nodePort: 30301 protocol: TCP type: NodePort
可以通过以下方法获得公网IP和服务端口:
kubectl get svc company-manager -o yaml | grep ExternalIP -C 1kubectl get svc company-manager -o yaml | grep nodePort -C 1
接下来你就可以使用公网IP和服务端口访问已经部署好的company了,在github.com/ServiceComb/ServiceComb-Company-WorkShop/kubernetes上详细提供了通过在集群内访问和集群外访问的方法。
模型归纳
通过详细阅读所有的deployment.yaml和service.yaml,可以整理出以下的模型:
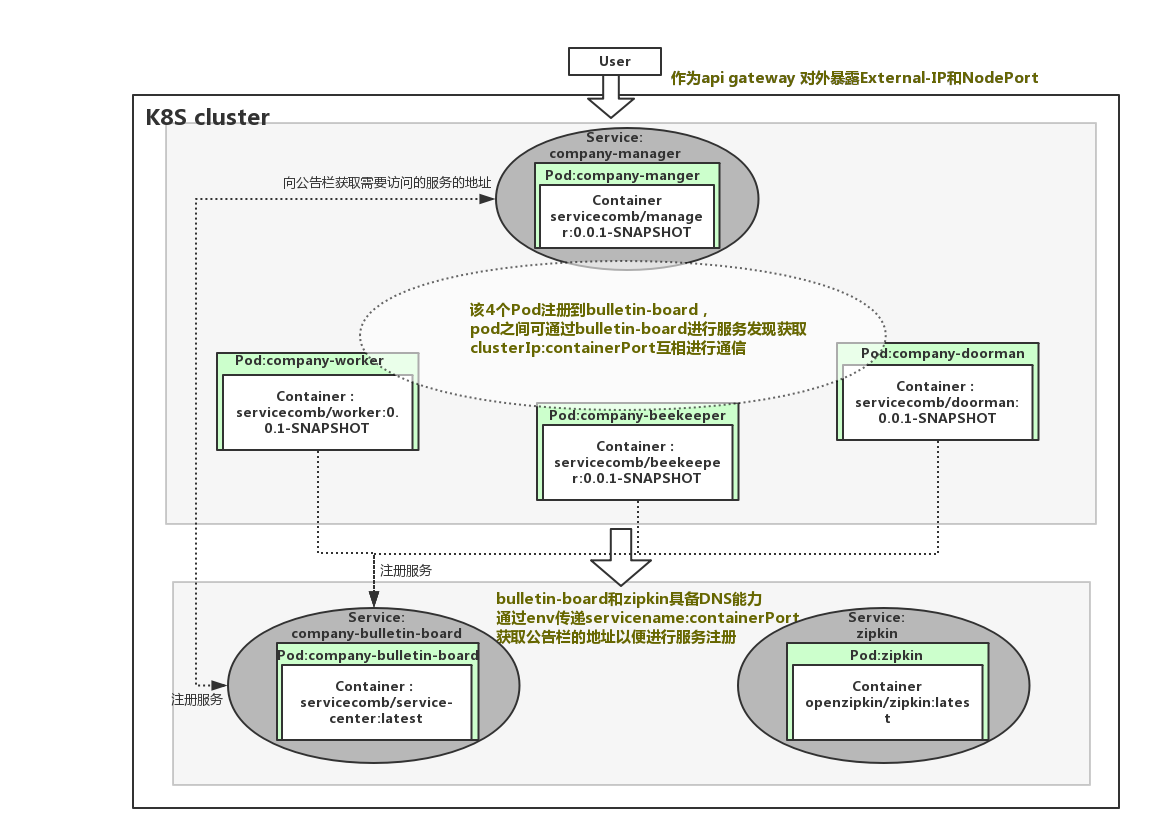
另外,经典的航空订票系统Acmeair也已经支持在kubernetes上一键式部署基于ServiceComb框架开发的版本,点击访问Run Acmeair on Kubernetes获取 。
弹性伸缩
本小节将继续在K8S上演示使用K8S的弹性伸缩能力进行Company示例的按需精细化资源控制,以此体验微服务化给大家带来的好处。
环境准备
K8S环境准备:
为使K8S具备弹性伸缩能力,需要先在K8S中安装监控器Heapster和Grafana:
具体读者踩了坑后更新的heapster的安装脚本作者放在:heapster,可直接获取下载获取,需要调整一个参数,后直接运行kube.sh脚本进行安装。
vi LinuxCon-Beijing-WorkShop/kubernetes/heapster/deploy/kube-config/influxdb/heapster.yaml
spec: replicas: 1 template: metadata: labels: task: monitoring k8s-app: heapster spec: serviceAccountName: heapster containers: - name: heapster image: gcr.io/google_containers/heapster-amd64:v1.4.1 imagePullPolicy: IfNotPresent command: - /heapster#集群内安装直接使用kubernetes - --source=kubernetes#集群外安装请直接将下面的服务地址替换为k8s api server地址# - --source=kubernetes:http://10.229.43.65:6443?inClusterConfig=false - --sink=influxdb:http://monitoring-influxdb:8086
启动Company:
下载Comany支持弹性伸缩的代码:
git clone https://github.com/ServiceComb/ServiceComb-Company-WorkShop.git cd LinuxCon-Beijing-WorkShop/kubernetes/ bash start-autoscale.sh
在Company的deployment.yaml中, 增加了如下限定资源的字段,这将限制每个pod被限制在200mill-core(1000毫core == 1 core)的cpu使用率以内。
resources: limits: cpu: 200m
在 start-autoscale.sh 中,对每个deployment创建HPA(pod水平弹性伸缩器)资源,限定每个pod的副本数弹性伸缩时控制在1到10之间,并限定每个pod的cpu占用率小于50%,结合前面限定了200mcore,故,每个pod的的平均cpu占用率会被HPA通过弹性伸缩能力控制在100mcore以内。
# Create Horizontal Pod Autoscalerkubectl autoscale deployment zipkin --cpu-percent=50 --min=1 --max=10kubectl autoscale deployment company-bulletin-board --cpu-percent=50 --min=1 --max=10kubectl autoscale deployment company-worker --cpu-percent=50 --min=1 --max=10kubectl autoscale deployment company-doorman --cpu-percent=50 --min=1 --max=10kubectl autoscale deployment company-manager --cpu-percent=50 --min=1 --max=10kubectl autoscale deployment company-beekeeper --cpu-percent=50 --min=1 --max=10
当运行start-autoscale.sh之后,具备弹性伸缩器的company已经被创建,可通过下面指令进行HPA的查询:
kubectl get hpa
启动压测:
export $HOST=<heapster-ip>:<heapster-port>bash LinuxCon-Beijing-WorkShop/kubernetes/stress-test.sh
该脚本不断循环执行 1s内向Company请求计算 fibonacci 数值200次,对Company造成请求压力:
FIBONA_NUM=`curl -s -H "Authorization: $Authorization" -XGET "http://$HOST/worker/fibonacci/term?n=6"`
测试过程与结果
分别查看HPA状态以及Grafana,如下:
图1 启动阶段

图2 启动阶段
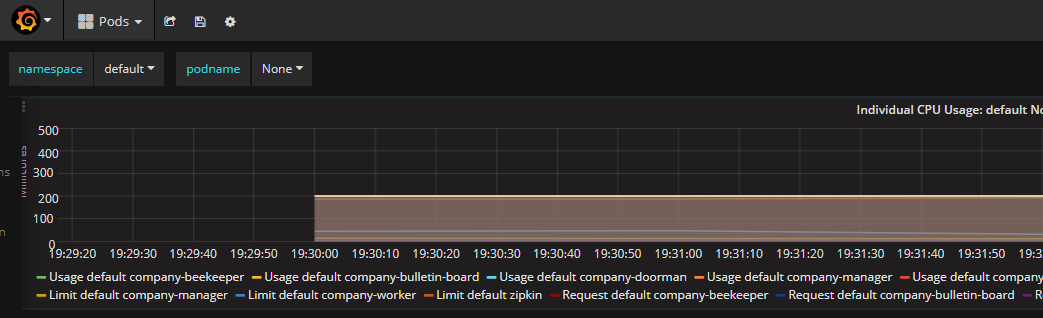
图3 过程
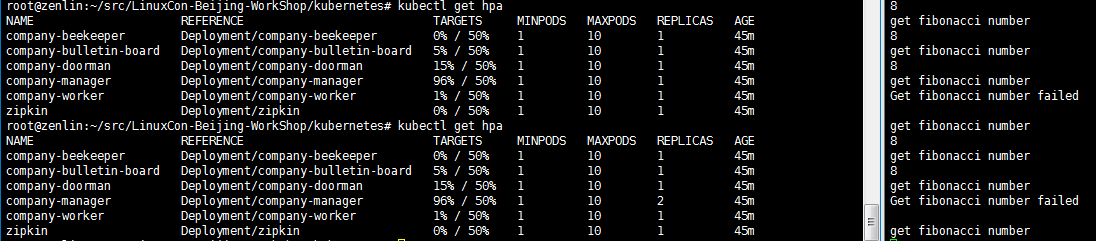
图4 结果
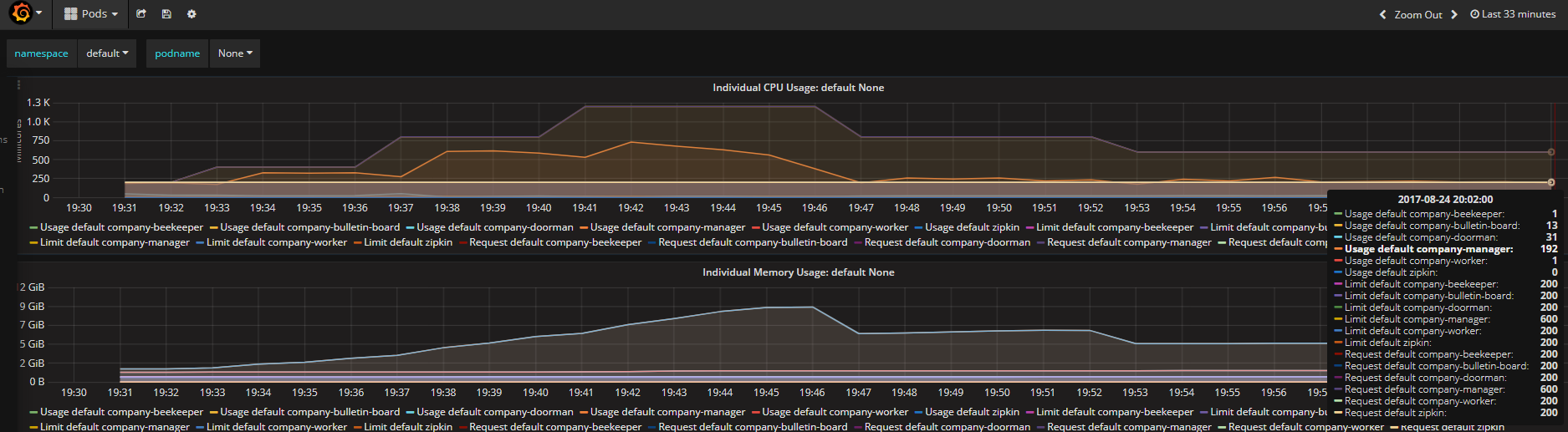
图5 结果

从以上过程可以分析出,以下几点:
1. 压力主要集中在company-manager这个pod上,K8S的autoscaler通过弹性增加该pod的副本数量,最终达到目标:每个pod的cpu占用率低于限定值的50%(图5,Usage default company-manager/Request default company-manager = 192/600 约等于图4中的33%),并保持稳定。
2. 在弹性伸缩过程中,在还没稳定前可能造成丢包,如图3。
3. Company启动会导致系统资源负载暂时性加大,故Grafana上看到的cpu占用率曲线会呈现波峰状,但随着系统稳定运行后,HPA会按照系统的稳定资源消耗准确找到匹配的副本数。图3中副本数已超过实际所需3个,但随着系统稳定,最终还是稳定维持在3个副本。
4. 在HPA以及Grafana可以看到缩放和报告数据都会有延迟,按照官方文档说法,只有在最近3分钟内没有重新缩放的情况下,才会进行放大。 从最后一次重新缩放,缩小比例将等待5分钟。 而且,只有在avg/ Target降低到0.9以下或者增加到1.1以上(10%容差)的情况下,才可能会进行缩放。
以上,就是本次对Compan示例弹性伸缩的全过程,Martin Fowler 在2014年3月的文章中提到:
微服务是一种架构风格,一个大型复杂软件应用由一个或多个微服务组成。系统中的各个微服务可被独立部署,各个微服务之间是松耦合的。每个微服务仅关注于完成一件任务并很好地完成该任务。在所有情况下,每个任务代表着一个小的业务能力。
国内实践微服务的先行者王磊先生也在《微服务架构与实践》一书中进行了全面论述。
Company使用ServiceComb进行微服务化改造后,具备了微服务的属性,故可以对单个负载较大的company-manager这个微服务进行精细化的控制,达到按需的目的,相比传统单体架构来讲,这将大大帮助准确有效地化解应用瓶颈,提高资源的利用效率。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



