
参考文献:Hyperband: Bandit-Based Configuration Evaluation for Hyperparameter Optimization
I. 传统优化算法
机器学习中模型性能的好坏往往与超参数(如batch size,filter size等)有密切的关系。最开始为了找到一个好的超参数,通常都是靠人工试错的方式找到"最优"超参数。但是这种方式效率太慢,所以相继提出了网格搜索(Grid Search, GS) 和 随机搜索(Random Search,RS)。
但是GS和RS这两种方法总归是盲目地搜索,所以贝叶斯优化(Bayesian Optimization,BO) 算法闪亮登场。BO算法能很好地吸取之前的超参数的经验,更快更高效地最下一次超参数的组合进行选择。但是BO算法也有它的缺点,如下:
对于那些具有未知平滑度和有噪声的高维、非凸函数,BO算法往往很难对其进行拟合和优化,而且通常BO算法都有很强的假设条件,而这些条件一般又很难满足。
为了解决上面的缺点,有的BO算法结合了启发式算法(heuristics),但是这些方法很难做到并行化
II. Hyperband算法
1. Hyperband是什么
为了解决上述问题,Hyperband算法被提出。在介绍Hyperband之前我们需要理解怎样的超参数优化算法才算是好的算法,如果说只是为了找到最优的超参数组合而不考虑其他的因素,那么我们那可以用穷举法,把所有超参数组合都尝试一遍,这样肯定能找到最优的。但是我们都知道这样肯定不行,因为我们还需要考虑时间,计算资源等因素。而这些因素我们可以称为Budget,用BB表示。
假设一开始候选的超参数组合数量是nn,那么分配到每个超参数组的预算就是BnBn。所以Hyperband做的事情就是在nn与BnBn做权衡(tradeoff)。
上面这句话什么意思呢?也就是说如果我们希望候选的超参数越多越好,因为这样能够包含最优超参数的可能性也就越大,但是此时分配到每个超参数组的预算也就越少,那么找到最优超参数的可能性就降低了。反之亦然。所以Hyperband要做的事情就是预设尽可能多的超参数组合数量,并且每组超参数所分配的预算也尽可能的多,从而确保尽可能地找到最优超参数。
2. Hyperband算法
Hyperband算法对 Jamieson & Talwlkar(2015)提出的SuccessiveHalving算法做了扩展。所以首先介绍一下SuccessiveHalving算法是什么。
其实仔细分析SuccessiveHalving算法的名字你就能大致猜出它的方法了:假设有nn组超参数组合,然后对这nn组超参数均匀地分配预算并进行验证评估,根据验证结果淘汰一半表现差的超参数组,然后重复迭代上述过程直到找到最终的一个最优超参数组合。
基于这个算法思路,如下是Hyperband算法步骤:

r: 单个超参数组合实际所能分配的预算;
R: 单个超参数组合所能分配的最大预算;
smaxsmax: 用来控制总预算的大小。上面算法中smax=logη(R)smax=logη(R),当然也可以定义为smax=logη(nmax)smax=logη(nmax)
B: 总共的预算,B=(smax+1)RB=(smax+1)R
ηη: 用于控制每次迭代后淘汰参数设置的比例
get_hyperparameter_configuration(n):采样得到n组不同的超参数设置
run_then_return_val_loss(t,ri):根据指定的参数设置和预算计算valid loss。LL表示在预算为riri的情况下各个超参数设置的验证误差
top_k(T,L,niηT,L,niη):第三个参数表示需要选择top k(k=niηk=niη)参数设置。
注意上述算法中对超参数设置采样使用的是均匀随机采样,所以有算法在此基础上结合贝叶斯进行采样,提出了BOHB:Practical Hyperparameter Optimization for Deep Learning
3. Hyperband算法示例
文中给出了一个基于MNIST数据集的示例,并将迭代次数定义为预算(Budget),即一个epoch代表一个预算。超参数搜索空间包括学习率,batch size,kernel数量等。
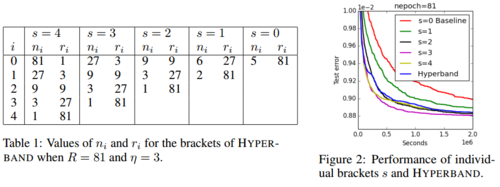
令R=81,η=3R=81,η=3,所以smax=4,B=5R=5×81smax=4,B=5R=5×81。
下图给出了需要训练的超参数组和数量和每组超参数资源分配情况。
由算法可以知道有两个loop,其中inner loop表示SuccessiveHalving算法。再结合下图左边的表格,每次的inner loop,用于评估的超参数组合数量越来越少,与此同时单个超参数组合能分配的预算也逐渐增加,所以这个过程能更快地找到合适的超参数。
右边的图给出了不同ss对搜索结果的影响,可以看到s=0s=0或者s=4s=4并不是最好的,所以并不是说ss越大越好。
共同学习,写下你的评论
评论加载中...
作者其他优质文章


