
做数据库开发的程序员,可能每天都会处理各种各样的查询sql,这个就是查找(Search)。通过查询记录主键字段(即主关键码)或其它非唯一字段(即次关键码)找到所需要的记录。
如果在查找的过程中,不改变原始数据(的数据结构),则这种查找称为静态查找(Static Search);如果找不到,需要向数据库里插入记录(或者找到了,需要从数据库里删除),这种在查找过程中需要动态调整原始数据(的数据结构),这种查找称为动态查找(Dynamic Search).
被查找的数据结构(比如数据库中的某张表)称为查找表,用于静态查找的称为静态查找表,反之则称为动态查找表。
一、静态查找
因为静态查找中不需要删除或新增记录,所以用顺序表比较适合。
1.1 顺序查找(Sequnce Search)
因为查找表为线性结构,所以也被称为线性查找(Linear Search),其思路很简单:从顺序表的一端向另一端逐个扫描,找到要的记录就返回其位置,找不到则返回失败信息(通常为-1)。
/// <summary>
/// 顺序查找
/// </summary>
/// <param name="arr">要查找的顺序表(比如数组)</param>
/// <param name="key">要查找的值</param>
/// <returns>找到返回元素的下标+1,否则返回-1</returns>
static int SeqSearch(int[] arr, int key)
{
int i = -1;
if (arr.Length <= 1) { return i; }
arr[0] = key;//第一个元素约定用来存放要查找的值,这个位置也称为“监视哨”,当然这并不是必须的,只是为了遵守原书的约定而已(以下同)
bool flag = false;
for (i = 1; i < arr.Length; i++)
{
if (arr[i] == key)
{
flag = true;
break;
}
}
if (!flag) { i = -1; }
return i;
}
1.2 二分查找(Binary Search)这种全表扫描的方法,虽然很容易理解,但是效率是很低的,特别是表中记录数很多时。如果查找表的记录本身是有序的,则可以用下面的办法改进效率
思路:因为查找表本身是有序的(比如从小到大排列),所以不必傻傻的遍历每个元素,可以取中间的元素与要查找的值比较,比如查找值大于中间元素,则要查找的元素肯定在后半段;反之如果查找值小于中间元素,则要查找的元素在前半段;然后继续二分,如此反复处理,直到找到要找的元素。
// <summary>
/// 二分查找(适用于有序表)
/// </summary>
/// <param name="arr">要查找的有序表</param>
/// <param name="key">要查找的值</param>
/// <returns>找到则返回元素的下标+1,否则返回-1</returns>
static int BinarySearch(int[] arr, int key)
{
arr[0] = key;//同样约定第一个位置存放要查找的元素值(仅仅只是约定而已)
int mid = 0;
int flag = -1;
int low = 1;
int high = arr.Length - 1;
while (low<=high)
{
//取中点
mid = (low + high) / 2;
//查找成功,记录位置存放到flag中
if (key == arr[mid])
{
flag = mid;
break;
}
else if (key < arr[mid]) //调整到左半区
{
high = mid - 1;
}
//调整到右半区
else
{
low = mid + 1;
}
}
if (flag > 0)
{
return flag;//找到了
}
else
{
return -1;//没找到
}
}二分查找性能虽然提高了不少,但是它要求查找表本身是有序的,这个条件太苛刻了,多数情况下不容易满足,那么如何将上面的二种方法结合在一起,又保证效率呢?
1.3 索引查找(Index Search)
思路:可以在查找表中选取一些关键记录,创建一个小型的有序表(该表中的每个元素除了记录自身值外,还记录了对应主查找表中的位置),即索引表。查找时,先到索引表中通过索引记录大致判断要查找的记录在主表的哪个区域,然后定位到主表的相应区域中,仅搜索这一个区块即可。
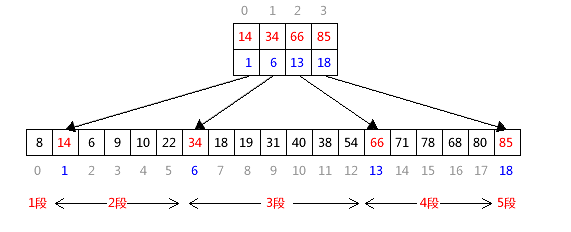
因为索引表本身是有序的,所以查找索引表时,可先用前面提到的二分查找判断大致位置,然后定位到主表中,用顺序查找。
比如:要查找值为78的记录,先到索引表中二分查找,能知道该记录,应该在主表索引13至18 之间(即第4段),然后定位到主表中的第4段顺序查找,如果找不到,则返回-1,反之则返回下标。
所以该方法的关键在于索引的建立!以上图为例,在主表中挑选关键值创建索引时,要求该关键值以前的记录都比它小,这样创建的索引表才有意义。
其实该思路在很多产品中都有应用,比如数据库的索引以及Lucene.Net都可以看作索引查找的实际应用。
顺便提一下:如果查找主表记录超级多,达到海量的级别,最终创建的索引表记录仍然很多,这样二分法查找还是比较慢,这时可以在索引表的基础上再创建一个索引的索引,称之为二级索引,如果二级索引仍然记录太多,可以再创建三级索引。
二、动态查找
动态查找中因为会经常要插入或删除元素,如果用数组来顺序存储,会导致大量的元素频繁移动,所以出于性能考虑,这次我们采用链式存储,并介绍一种新的树:二叉排序树(Binary Sort Tree)

上图就是一颗“二叉排序树 ”,其基本特征是:
1、不管是哪个节点,要么没有分支(即无子树)
2、如果有左分支,则左子树中的所有节点,其值都比它自身的值小
3、如果有右分支,则右子树中的所有节点,其值都比它自身的值大
2.1、二叉排序树的查找
思路:从根节点开始遍历,如果正好该根节点就是要找的值,则返回true,如果要查找的值比根节点大,则调整到右子树查找,反之调整到左子树。
/// <summary>
/// 二叉排序树查找
/// </summary>
/// <param name="bTree"></param>
/// <param name="key"></param>
/// <returns></returns>
static bool BiSortTreeSearch(BiTree<int> bTree, int key)
{
Node<int> p;
//如果树为空,则直接返回-1
if (bTree.IsEmpty())
{
return false;
}
p = bTree.Root;
while (p != null)
{
//如果根节点就是要找的
if (p.Data == key)
{
return true;
}
else if (key > p.Data)
{
//调整到右子树
p = p.RChild;
}
else
{
//调整到左子树
p = p.LChild;
}
}
return false;
}注:上面的代码中,用到了BiTree<T>这个类,在数据结构C#版笔记--树与二叉树 中可找到,为了验证该代码是否有效,可用下列代码测试一下:
//先创建树 BiTree<int> tree = new BiTree<int>(100); Node<int> root = tree.Root; Node<int> p70 = new Node<int>(70); Node<int> p150 = new Node<int>(150); root.LChild = p70; root.RChild = p150; Node<int> p40 = new Node<int>(40); Node<int> p80 = new Node<int>(80); p70.LChild = p40; p70.RChild = p80; Node<int> p20 = new Node<int>(20); Node<int> p45 = new Node<int>(45); p40.LChild = p20; p40.RChild = p45; Node<int> p75 = new Node<int>(75); Node<int> p90 = new Node<int>(90); p80.LChild = p75; p80.RChild = p90; Node<int> p112 = new Node<int>(112); Node<int> p180 = new Node<int>(180); p150.LChild = p112; p150.RChild = p180; Node<int> p120 = new Node<int>(120); p112.RChild = p120; Node<int> p170 = new Node<int>(170); Node<int> p200 = new Node<int>(200); p180.LChild = p170; p180.RChild = p200; //测试查找 Console.WriteLine(BiSortTreeSearch(tree, 170));
2.2、二叉排序树的插入
逻辑:先在树中查找指定的值,如果找到,则不插入,如果找不到,则把要查找的值插入到最后一个节点下做为子节点(即:先查找,再插入)
/// <summary>
/// 二插排序树的插入(即:先查找,如果找不到,则插入要查找的值)
/// </summary>
/// <param name="bTree"></param>
/// <param name="key"></param>
/// <returns></returns>
static bool BiSortTreeInsert(BiTree<int> bTree, int key)
{
Node<int> p = bTree.Root;
Node<int> last = null;//用来保存查找过程中的最后一个节点
while (p != null)
{
if (p.Data == key)
{
return true;
}
last = p;
if (key > p.Data)
{
p = p.RChild;
}
else
{
p = p.LChild;
}
}
//如果找了一圈,都找不到要找的节点,则将目标节点插入到最后一个节点下面
p = new Node<int>(key);
if (last == null)
{
bTree.Root = p;
}
else if (p.Data < last.Data)
{
last.LChild = p;
}
else
{
last.RChild = p;
}
return false;
}2.3 二叉排序树的创建
从刚才插入的过程来看,每个要查找的值,动态查找一次以后,就会被附加到树的最后,所以:"给定一串数字,将它们创建一棵二叉排序树"的思路就有了,依次把这些数字动态查找一遍即可。
/// <summary>
/// 创建一颗二插排序树
/// </summary>
/// <param name="tree"></param>
/// <param name="arr"></param>
/// <param name="index"></param>
static void CreateBiSortTree(BiTree<int> tree, int[] arr)
{
for (int i = 0; i < arr.Length; i++)
{
BiSortTreeInsert(tree, arr[i]);
}
}2.4 二叉排序树的节点删除
这也是动态查询的一种情况,找到需要的节点后,如果存在,则删除该节点。可以分为几下四种情况:
a.待删除的节点,本身就是叶节点
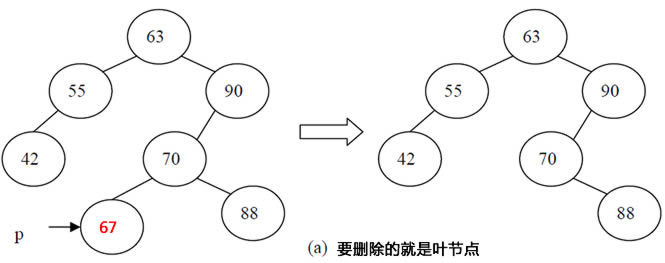
这种情况下最简单,只要把这个节点删除掉,然后父节点的LChild或RChild设置为null即可
b.待删除的节点,只有左子树

思路:将本节点的左子树上移,挂到父节点下的LChild,然后删除自身即可
c.待删除的节点,只有右子树

思路:将自身节点的右子树挂到父节点的左子树,然后删除自身即可
d.待删除的节点,左、右子树都有

思路:这个要复杂一些,先找出自身节点右子树中的左分支的最后一个节点(最小左节点),然后将它跟自身对调,同时将“最小左节点”下的分支上移。
以上逻辑综合起来,就得到了下面的方法:
/// <summary>
/// 删除二叉排序树的节点
/// </summary>
/// <param name="tree"></param>
/// <param name="key"></param>
/// <returns></returns>
static bool DeleteBiSort(BiTree<int> tree, int key)
{
//二叉排序树为空
if (tree.IsEmpty())
{
return false;
}
Node<int> p=tree.Root;
Node<int> parent = p;
while (p!=null)
{
if (p.Data == key)
{
if (tree.IsLeaf(p))//如果待删除的节点为叶节点
{
#region
if (p == tree.Root)
{
tree.Root = null;
}
else if (p == parent.LChild)
{
parent.LChild = null;
}
else
{
parent.RChild = null;
}
#endregion
}
else if ((p.RChild == null) && (p.LChild != null)) //仅有左分支
{
#region
if (p == parent.LChild)
{
parent.LChild = p.LChild;
}
else
{
parent.RChild = p.LChild;
}
#endregion
}
else if ((p.LChild == null) && (p.RChild != null)) //仅有右分支
{
#region
if (p == parent.LChild)
{
parent.LChild = p.RChild;
}
else
{
parent.RChild = p.RChild;
}
#endregion
}
else //左,右分支都有
{
//原理:先找到本节点右子树中的最小节点(即右子树的最后一个左子节点)
#region
Node<int> q = p;
Node<int> s = p.RChild;
while (s.LChild != null)
{
q = s;
s = s.LChild;
}
Console.WriteLine("s.Data=" + s.Data + ",p.Data=" + p.Data + ",q.Data=" + q.Data);
//然后将找到的最小节点与自己对调(因为最小节点是从右子树中找到的,所以其值肯定比本身要大)
p.Data = s.Data;
if (q != p)
{
//将q节点原来的右子树挂左边(这样最后一个节点的子树就调整到位了)
q.LChild = s.RChild;
}
else //s节点的父节点就是p时,将s节点原来的右树向上提(因为s已经换成p点的位置了,所以这个位置就不需要了,直接把它的右树向上提升即可)
{
q.RChild = s.RChild;
}
#endregion
}
return true;
}
else if (key>p.Data)
{
parent = p;
p = p.RChild;
}
else
{
parent = p;
p = p.LChild;
}
}
return false;
}
共同学习,写下你的评论
评论加载中...
作者其他优质文章



