
Lucene 高级搜索引擎工厂(一)
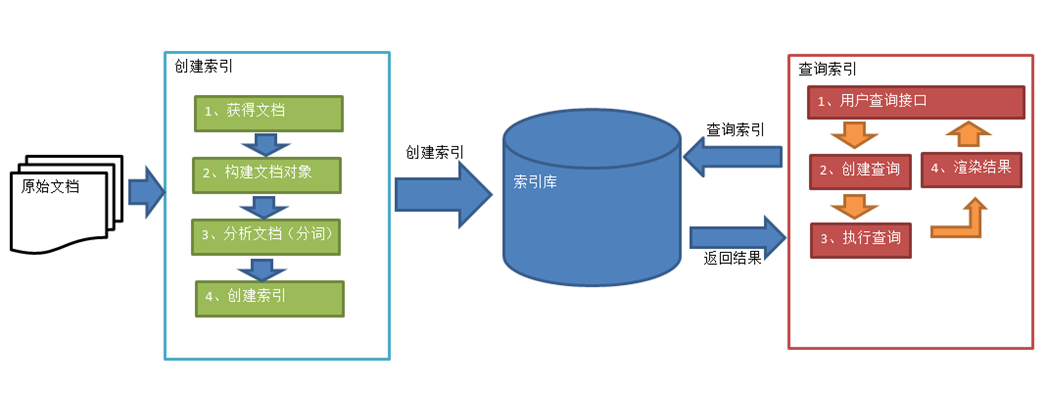
一、Lucene环境搭建
<lucene.version>7.5.0</lucene.version>
<!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-core -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>${lucene.version}</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>${lucene.version}</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>${lucene.version}</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>${lucene.version}</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queries</artifactId>
<version>${lucene.version}</version>
</dependency>
<dependency>
<groupId>com.xmbl</groupId>
<artifactId>IKAnalyzer</artifactId>
<version>6.5.0</version>
</dependency>
二、Lucene索引库创建
package com.xmbl.ops.config;
import java.nio.file.FileSystems;
import java.util.ArrayList;
import java.util.List;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.bson.Document;
import org.wltea.analyzer.lucene.IKAnalyzer;
import com.mongodb.MongoClient;
import com.mongodb.ServerAddress;
import com.mongodb.client.FindIterable;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import lombok.extern.slf4j.Slf4j;
/**
*
* Copyright © 2018 noseparte © BeiJing BoLuo Network Technology Co. Ltd.
* @Author Noseparte
* @Compile 2018年11月26日 -- 下午4:45:51
* @Version 1.0
* @Description Lucene 高级搜索引擎工厂
*/
@Slf4j
public class LuceneCommonFactory{
public static String INDEX_PATH = "";
// 分配lucene索引库的磁盘地址
static {
String os_name = System.getProperty("os.name");
if (os_name.toLowerCase().equals("win")) {
INDEX_PATH = "D:\\data\\lucene\\lucene-db";
}else
INDEX_PATH = "/data/lucene/lucene-db";
}
public static MongoClient client = null;
public static MongoDatabase database = null;
public static ServerAddress serverAddress = null;
public static List<ServerAddress> serverAddresses = new ArrayList<ServerAddress>();
/*
* mongo 配置常量
*/
private static String IP = MongoConfigUtil.queryValueByLoadProperties("mongodb_url_login");
private static String PORT = MongoConfigUtil.queryValueByLoadProperties("mongodb_port_login");
/**
* Mongo驱动加载数据库连接
* {@linkplain mongoDB从3.0开始支持mongoClient客户端,连接mongoDB数据库(增删改查) }
*/
public static void getMongoConn() {
try {
// Mongo服务的地址 类似JDBC (Java DataBase Connectivity)
serverAddress = new ServerAddress(IP, Integer.parseInt(PORT));
serverAddresses.add(serverAddress);
// MongoCredential 连接mongo的凭证,需注意password为{ final char[] password }
client = new MongoClient(serverAddresses);
} catch (Exception e) {
log.info("mongoDriver连接失败: errorMsg,{}",e.getMessage());
}
if(null != client) {
database = client.getDatabase("login");
}
}
public static MongoClient getMongoClient() {
if(null == client) {
getMongoConn();
}
return client;
}
/**
* 获取database
*
* @return
*/
public static MongoDatabase getDatabase() {
if (null == client) {
getMongoConn();
}
return database;
}
/**
* 获取User Collection
*
* @return
*/
public static MongoCollection<org.bson.Document> getCollection() {
if (null == database) {
database = getDatabase();
}
if (null != database) {
return database.getCollection("app_user");
}
return null;
}
// 原始文档 ==> 创建索引
// 1.获得文档; 2.构架文档对象; 3.分析文档(分词); 4.创建索引;
/**
* 见数据库文件生成本地索引文件,创建索引
* {@link https://www.cnblogs.com/dacc123/p/8228298.html}
* {@linkplain 索引的创建 IndexWriter 和索引速度的优化 }
*/
public static void createIndex() {
IndexWriter indexWriter = null;
try {
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath(INDEX_PATH));
// 根据空格和符号来完成分词,还可以完成数字、字母、E-mail地址、IP地址以及中文字符的分析处理,还可以支持过滤词表,用来代替StopAnalyzer能够实现的过滤功能。
// Analyzer analyzer = new StandardAnalyzer();
// 实现了以词典为基础的正反向全切分,以及正反向最大匹配切分两种方法。IKAnalyzer是第三方实现的分词器,继承自Lucene的Analyzer类,针对中文文本进行处理。
Analyzer analyzer = new IKAnalyzer(true);
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);
indexWriterConfig.setRAMBufferSizeMB(16.0);
indexWriter = new IndexWriter(directory, indexWriterConfig);
long deleteCount = indexWriter.deleteAll(); // 清楚以前的索引
log.info("索引库清除完毕,清除数量为,deleteCount,{}",deleteCount);
MongoCollection<Document> collection = getCollection();
FindIterable<Document> Documents = collection.find();
for(Document cursor : Documents) {
org.apache.lucene.document.Document document = new org.apache.lucene.document.Document();
document.add(new Field("id", cursor.getObjectId("_id").toString(), TextField.TYPE_STORED));
document.add(new Field("userkey", cursor.getString("userkey"), TextField.TYPE_STORED));
indexWriter.addDocument(document);
}
} catch (Exception e) {
log.error("创建索引失败。 errorMsg,{}",e.getMessage());
} finally {
try {
if (null != indexWriter) {
indexWriter.close();
}
} catch (Exception ex) {
log.error("索引流关闭失败,error,{}",ex.getMessage());
}
}
}
public static void main(String[] args) {
createIndex();
}
}
点击查看更多内容
1人点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中



感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦