
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用的功能。Flink将流处理和批处理统一起来,也就是说作为流处理看待时输入数据流是无界的;批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。
Flink特点
支持高吞吐、低延迟、高性能的流处理
支持有状态计算的Exactly-once语义
支持高度灵活的窗口(Window)操作,支持基于time、count、session,以及data-driven的窗口操作
支持基于轻量级分布式快照(Snapshot)实现的容错
一个运行时同时支持Batch on Streaming处理和Streaming处理
Flink在JVM内部实现了自己的内存管理
支持程序自动优化:避免特定情况下Shuffle、排序等昂贵操作,中间结果有必要进行缓存
支持迭代计算
Flink组件栈
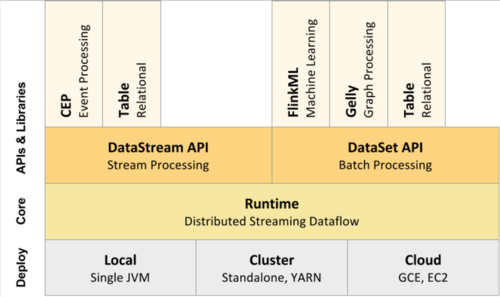
Flink以层级式系统形式组件其软件栈、上层依赖下层服务
支持 local、cluster、cloud运行模式
运行时,将dataStream 和 dataSet抽象成jobGraph
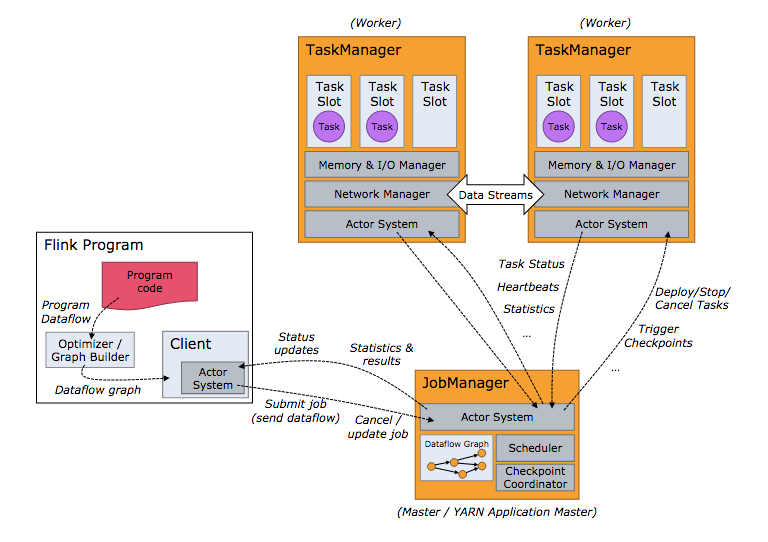
Flink进程
JobManagers(master):用于协调分布式程序执行。它们用来调度task,协调检查点,协调失败时恢复等
TaskManagers(worker):用于执行一个dataflow的task(或者特殊的subtask)、数据缓冲和data stream的交换。
flink应用程序的执行流程图——standalone

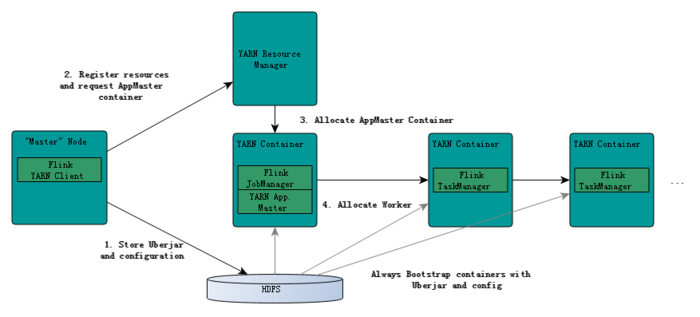
flink应用程序的执行流程图——flink on yarn
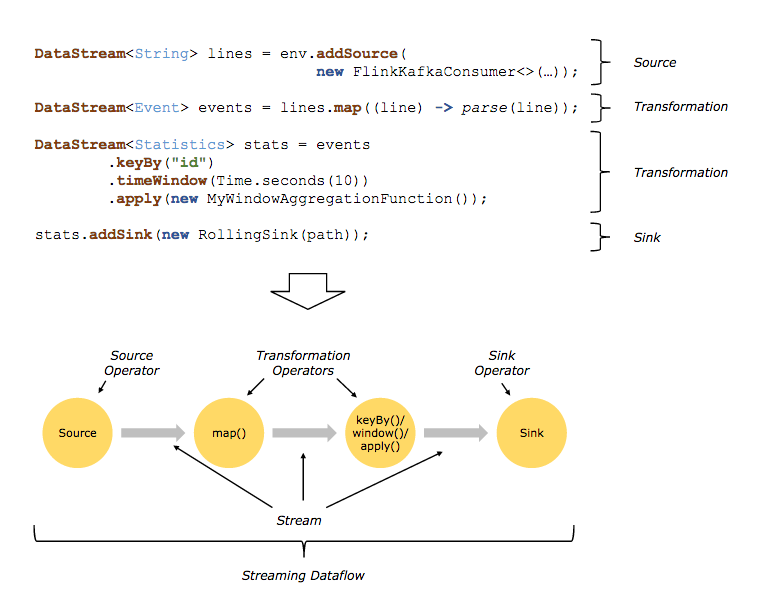
Flink程序的核心概念
flink程序三个基本构建块
source:数据源
transformations:基于数据流的一组operate操作
sink:数据处理结果的目的地
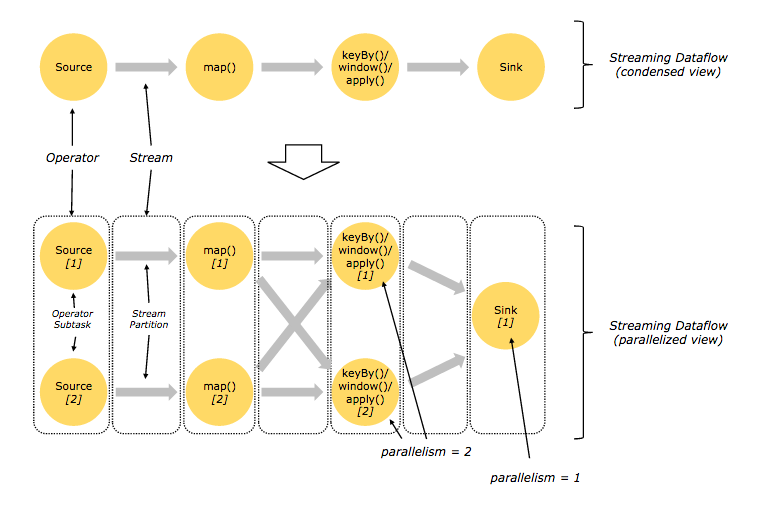
并行数据流
One-to-one:类似于spark中的窄依赖
Redistributing:类似于spark中的宽依赖
在flink中,transformation是由一组operator组成,每一个operator被分割成operator subtask,同一个operator的多个 subtasks在不同的线程、不同的物理机或不同的容器中彼此互不依赖得并行执行。
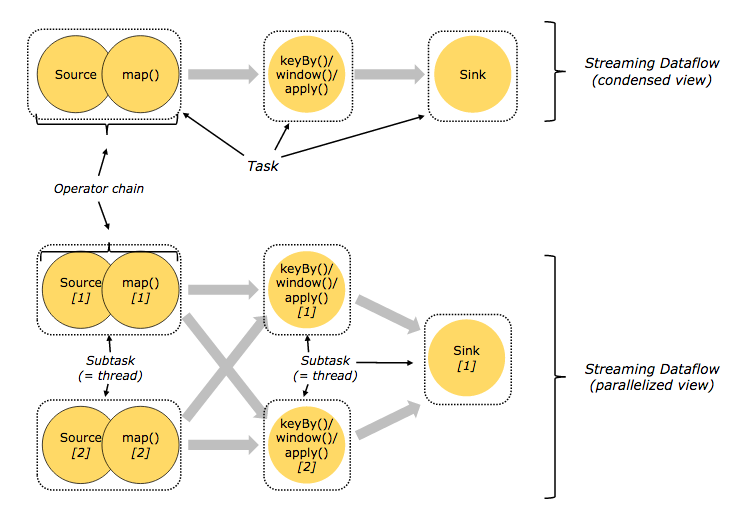
Stream在operator有两种形式
operator chains
出于分布式程序效率考虑,Flink将前后有依赖关系的一组operator的subtask链接在一起形成operator chains。operator chain在一个线程中执行,它能减少线程之间的切换和基于缓存区的数据交换,在减少时延的同时提升吞吐量。链接的行为可以在编程API中进行指定
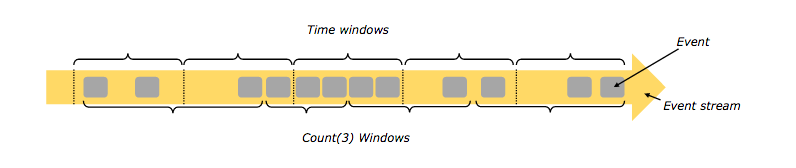
窗口
flink可以基于窗口对在流上对数据进行聚合操作。flink支持的窗口有:
时间窗口(tumbing windows(不重叠),sliding windows(有重叠,session windows(有空隙的活动))
数据窗口(tumbing windows(不重叠),sliding windows(有重叠,session windows(有空隙的活动))
事件窗口
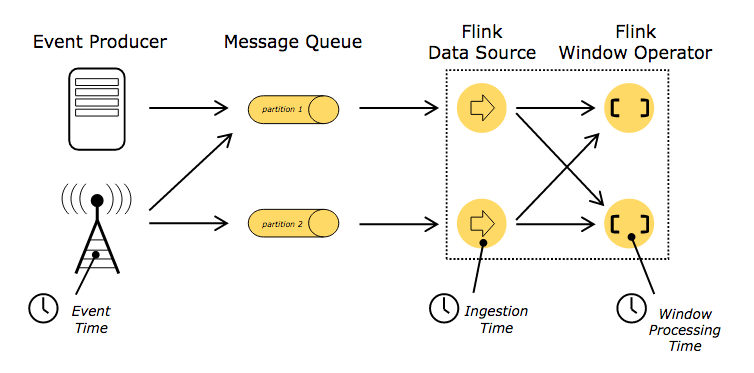
时间
Stream中的记录时,记录中通常会包含各种典型的时间字段,Flink支持多种时间的处理:
event Time:表示事件创建时间
Ingestion Time:表示事件进入到Flink Dataflow的时间
Processing Time:表示某个Operator对事件进行处理事的本地系统时间(是在TaskManager节点上)
共同学习,写下你的评论
评论加载中...
作者其他优质文章



