
前言
上篇博客的内容是守护进程,对于操作系统来说可以在后台执行一些程序.这篇的内容是互斥锁,在上上篇博客上说到进程内存空间互相隔离,所以可以通过共享文件来操作同一个文件,那么这样操作的话会发生什么呢?
锁
互斥锁
多个进程需要共享数据时,先将其锁定,此时资源状态为'锁定',其他进程不能更改;知道该进程释放资源,将资源的状态变成非'锁定',其他的线程才能再次锁定该资源.互斥锁保证了每次只有一个进程进入写入操作,从而保证了多进程情况下数据的正确性.
我们使用一个demo 来模拟多个进程操作同一个文件:
import jsonimport time,randomfrom multiprocessing import Processdef show_tickets(name):
time.sleep(random.randint(1,3)) with open('ticket.json', 'rt', encoding='utf-8') as f:
data = json.load(f)
print('%s 查看 剩余票数: %s' % (name, data['count']))def buy_ticket(name):
with open('ticket.json', 'rt', encoding='utf-8') as f:
dic = json.load(f) if dic['count'] > 0:
dic['count'] -= 1
time.sleep(random.randint(1,3)) with open('ticket.json', 'wt', encoding='utf-8') as f:
json.dump(dic, f)
print('%s: 购票成功' % name)def task(name):
show_tickets(name)
buy_ticket(name)if __name__ == '__main__': for i in range(1,11):
p = Process(target=task, args=(i,))
p.start()运行结果:
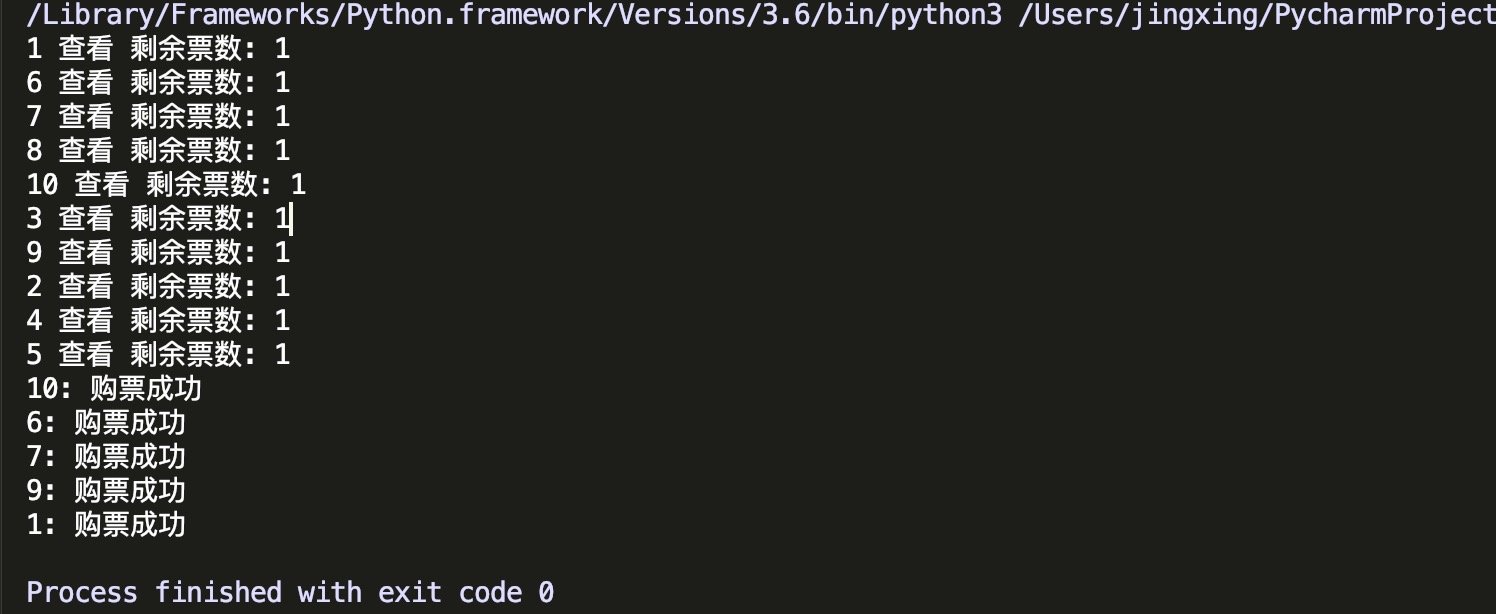
在 ticket.json 里面只有一张票,结果却造成多个用户购买成功,这很显然是不符合实际情况的.
那么怎么解决呢?如果多个进程对同一个文件进行读操作可以不进行限制,但是对同一个文件进行写操作就必要要进行限制,不可以同时多个人对同一个文件进行写操作.python 在多进程模块里提供一个类, Lock 类,当进程获取到锁的时候其他的进程就必须要等待锁释放才可以进行争抢,在这个例子里面就可以加上一把锁来保护数据安全.
from multiprocessing import Process, Lockimport json,time,randomdef show_tickets(name):
time.sleep(random.randint(1,3)) with open('ticket.json', 'rt', encoding='utf-8') as f:
data = json.load(f)
print('%s 查看 剩余票数: %s' % (name, data['count']))def buy_ticket(name):
time.sleep(random.randint(1,3)) with open('ticket.json', 'rt', encoding='utf-8') as f:
dic = json.load(f) if dic['count'] > 0:
dic['count'] -= 1
time.sleep(random.randint(1,3)) with open('ticket.json', 'wt', encoding='utf-8') as f:
json.dump(dic, f)
print('%s: 购票成功' % name)def task(name,lock):
show_tickets(name)
lock.acquire()
buy_ticket(name)
lock.release()if __name__ == '__main__':
mutex = Lock() for i in range(1,11):
p = Process(target=task, args=(i,mutex))
p.start()运行结果:
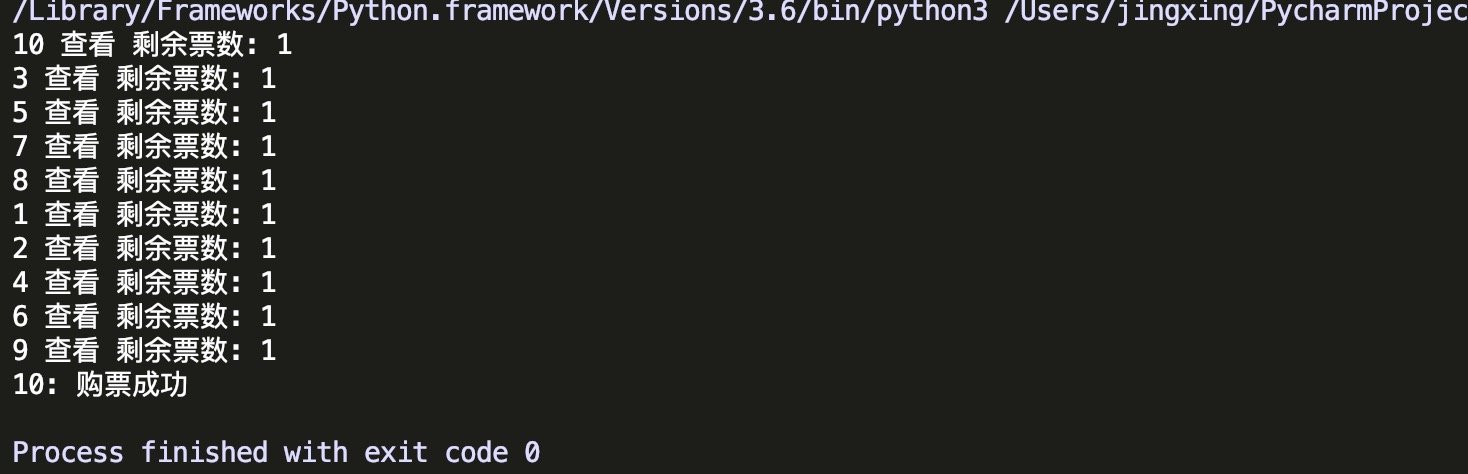
这样加了锁(互斥锁)就可以解决同时操作同一个文件造成的数据混乱问题了.
当使用多进程开发时,如果多个进程同时读写同一个资源,可能会造成数据的混乱,为了防止发生问题,使用锁,或者使用 Process 的方法 join 将并行变为串行.
join 和锁的区别
join 人为控制进程的执行顺序
join 把整个进程全部串行,而锁可以指定部分代码串行
一旦串行,效率就会降低,一旦并行,数据就可能会出错.
进程间通信
进程间通信( internal-process communication),我们在开启子进程是希望子进程帮助完成任务,很多情况下需要将数据返回给父进程,然而进程间内存是物理隔离的.
解决办法:
将共享数据放到文件中
管道 多进程模块中的一个类,需要有父子关系
共享一快内存区域 需要操作系统分配
管道通信
Pipe类返回一个由管道连接的连接对象,默认情况下为双工:
from multiprocessing import Process,Pipedef f(conn): conn.send([42, None, 'hello']) conn.close() if __name__ == '__main__': parent_conn, child_conn = Pipe() p = Process(target=f, args=(child_conn,)) p.start() print(parent_conn.recv()) p.join()
运行结果:
[42, None, 'hello']
实例化 Pipe 类会返回两个连接对象表示管道的两端.每个连接对象都有 send() 和 recv() 方法(及其他).请注意,如果两个进程同时尝试读写管道的同一端,则管道中的数据可能会损坏.当然,同时使用管道的不同端部的过程不存在损坏的风险.
共享内存通信
Queue 通信
Queue类会生成一个先进先出的容器,通过往队列中存取数据而进行进程间通信.
from multiprocessing import Process, Queuedef f(q): q.put([42, None, 'hello']) if __name__ == '__main__': q = Queue() p = Process(target=f, args=(q,)) p.start() print(q.get()) p.join()
运行结果:
[42, None, 'hello']
队列其他特性
# 阻塞操作 必须掌握q = Queue(3)# # 存入数据q.put("hello",block=False)
q.put(["1","2","3"],block=False)
q.put(1,block=False)# 当容量满的时候 再执行put 默认会阻塞直到执行力了get为止# 如果修改block=False 直接报错 因为没地方放了# q.put({},block=False)# # # 取出数据print(q.get(block=False))
print(q.get(block=False))
print(q.get(block=False))# 对于get 当队列中中没有数据时默认是阻塞的 直达执行了put# 如果修改block=False 直接报错 因为没数据可取了print(q.get(block=False))# 了解q = Queue(3)
q.put("q",timeout=3)
q.put("q2",timeout=3)
q.put("q3",timeout=3)# 如果满了 愿意等3秒 如果3秒后还存不进去 就炸# q.put("q4",timeout=3)print(q.get(timeout=3))
print(q.get(timeout=3))
print(q.get(timeout=3))# 如果没了 愿意等3秒 如果3秒后还取不到数据 就炸print(q.get(timeout=3))Manager 通信
demo
from multiprocessing import Process,Managerimport timedef task(dic):
print("子进程xxxxx") # li[0] = 1
# print(li[0])
dic["name"] = "xx"if __name__ == '__main__':
m = Manager() # li = m.list([100])
dic = m.dict({}) # 开启子进程
p = Process(target=task,args=(dic,))
p.start()
time.sleep(3)可以创建一片共享内存区域用来存取数据.
生产者消费者模型
什么是生产者消费者模型
在软件开发过程中,经常碰到这样的场景:
某些模块负责生产数据,这些数据由其他模块来负责处理(此处的模块可能是:函数,线程,进程等).生产数据的模块称为生产者,而处理数据的模块称为消费者.在生产者与消费者之间的缓冲区称之为仓库.生产者负责往仓库运输商品,而消费者负责从仓库里取出商品,这就构成了生产者消费者模型.
结构图如下:
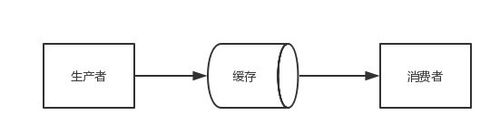
为了便于理解,我们举一个寄信的例子。假设你要寄一封信,大致过程如下:
你把信写好——相当于生产者生产数据;
你把信放入邮箱——相当于生产者把数据放入缓冲区;
邮递员把信从邮箱取出,做相应处理——相当于消费者把数据取出缓冲区,处理数据.
生产者消费者模型的优点
解耦
假设生产者和消费者分别是两个线程.如果让生产者直接调用消费者的某个方法,那么生产者对于消费者就会产生依赖(耦合).如果未来消费者的代码发生改变,可能会影响到生产者的代码.而如果两者都依赖于某个缓冲区,两者之间不直接依赖,耦合也就相应降低了.
举个例子,我们去邮局投递信件,如果不使用邮箱(也就是缓冲区,你必须得把信直接交给邮递员.有同学会说,直接给邮递员不是挺简单的嘛?其实不简单,你必须 得认识谁是邮递员,才能把信给他.这就产生了你和邮递员之间的依赖(相当于生产者和消费者的强耦合).万一哪天邮递员换人了,你还要重新认识一下(相当于消费者变化导致修改生产者代码).而邮箱相对来说比较固定,你依赖它的成本就比较低(相当于和缓冲区之间的弱耦合).
并发
由于生产者与消费者是两个独立的并发体,它们之间是使用缓冲区通信的,生产者只需要往缓冲区里丢数据,就可以接着生产下一个数据了,而消费者只需要从缓冲区拿数据即可,这样就不会因为彼此的处理速度而发生阻塞.
继续上面的例子,如果没有邮箱,就得在邮局等邮递员,知道他回来,把信交给他,这期间我们什么事都干不了(生产者阻塞).或者邮递员挨家挨户问,谁要寄信(消费者阻塞).
支持忙闲不均
当生产者制造数据快的时候,消费者来不及处理,为处理的数据可以暂时存在缓冲区中,慢慢处理,而不至于因为消费者的性能过慢造成数据丢失或影响生产者生产数据.
再拿寄信的例子,假设邮递员一次只能带走1000封信,万一碰上情人节或者其他的紧急任务,需要寄出的信超过了1000封,这个时候邮箱作为缓冲区就派上用场了.邮递员把来不及带走的信暂存在邮箱中,等下次过来时在拿走.
使用
from multiprocessing import Process, Queueimport time, randomdef producer(name, food, q):
for i in range(10):
res = '%s %s' % (food, i)
time.sleep(random.randint(1,3))
q.put(res)
print('%s 生产了 %s' % (name, res))
def consumer(name, q):
while True:
res = q.get()
time.sleep(random.randint(1,3))
print('%s 消费了 %s' % (name, res))if __name__ == '__main__':
q = Queue()
p = Process(target=producer, args=('musibii', '', q))
c = Process(target=consumer, args=('thales', q))
p.start()
c.start()
p.join()
c.join()
print('主进程')运行结果:
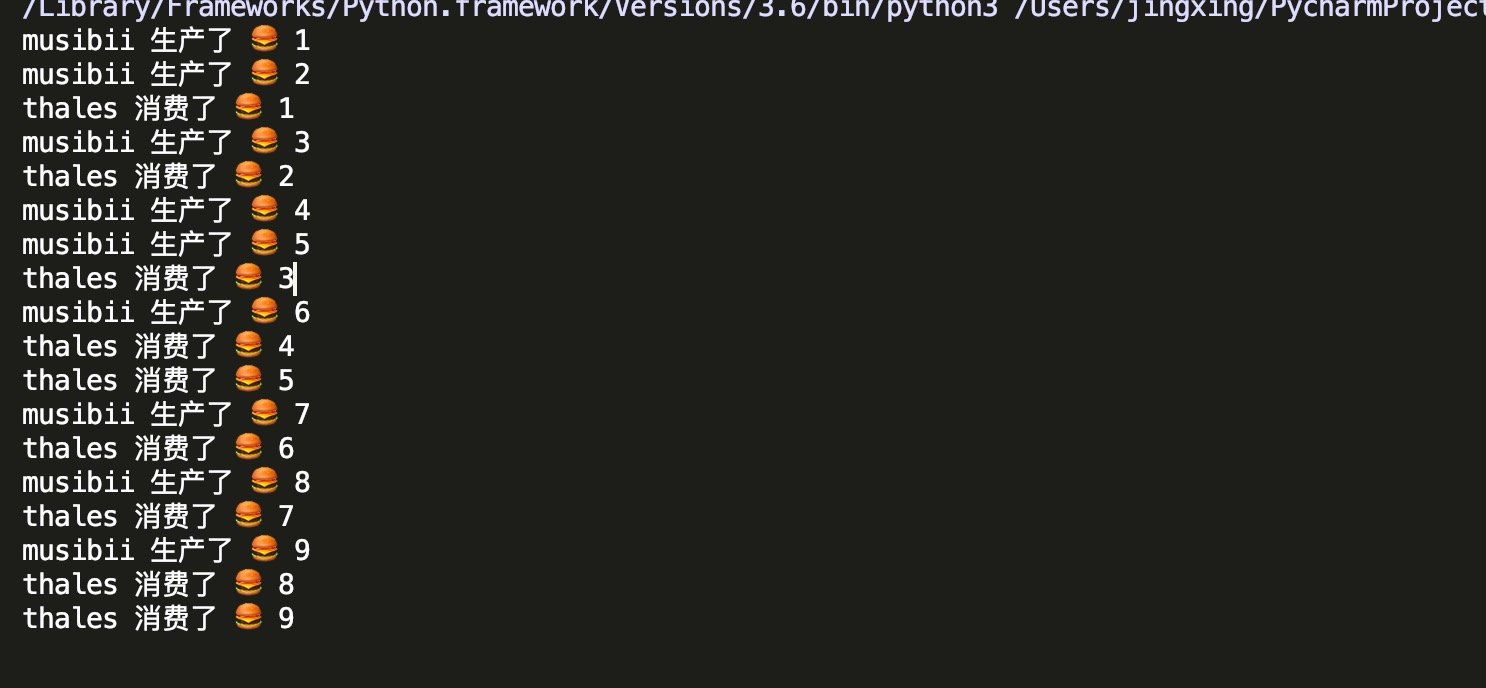
这样的话该进程并不会结束,因为 get 方法是阻塞的,数据消费完就会一直等待知道生产者生产新的数据,而生产者只能生产9个数据.所以会一直阻塞.
改进使用
我们需要在消费者消费的时候知道队列里面有多少数据,应该什么时候消费完了,所以可以在生产者里面生产结束后添加一个标志,比如 None.
import time, randomfrom multiprocessing import Process, Queue# 制作热狗def make_hotdog(queue, name):
for i in range(1, 4):
time.sleep(random.randint(1, 2))
print("%s 制作了一个 %s" % (name, i)) # 生产得到的数据
data = "%s 生产的%s" % (name, i) # 存到队列中
queue.put(data) # 装入一个特别的数据 告诉消费方 没有了
# queue.put(None)# 吃热狗def eat_hotdog(queue, name):
while True:
data = queue.get() if not data: break
time.sleep(random.randint(1, 2))
print("%s 吃了 %s" % (name, data))if __name__ == '__main__': # 创建队列
q = Queue()
p1 = Process(target=make_hotdog, args=(q, "musibii的热狗店"))
p2 = Process(target=make_hotdog, args=(q, "egon的热狗店"))
p3 = Process(target=make_hotdog, args=(q, "eureka的热狗店"))
c1 = Process(target=eat_hotdog, args=(q, "thales"))
c2 = Process(target=eat_hotdog, args=(q, "maffia"))
p1.start()
p2.start()
p3.start()
c1.start()
c2.start() # 让主进程等三家店全都做完后....
p1.join()
p2.join()
p3.join() # 添加结束标志 注意这种方法有几个消费者就加几个None 不太合适 不清楚将来有多少消费者
q.put(None)
q.put(None) # 现在 需要知道什么时候做完热狗了 生产者不知道 消费者也不知道
# 只有队列知道
print("主进程over") # 生产方不生产了 然而消费方不知道 所以已知等待 get函数阻塞
# 三家店都放了一个空表示没热狗了 但是消费者只有两个 他们只要看见None 就认为没有了
# 于是进程也就结束了 造成一些数据没有被处理
# 等待做有店都做完热狗在放None运行结果:
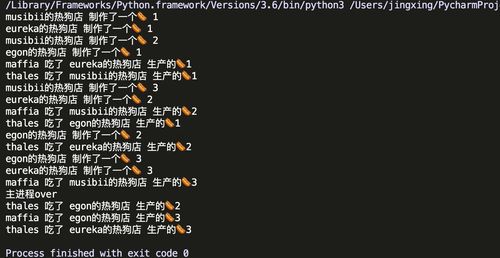
这样就解决了最初版本消费之因为没有数据而阻塞的问题了,但是这里还是有问题,因为不知道到底有多少消费者,因为想让消费者知道数据已经结束了的话,需要给每个消费者一个标志位,这样是不现实的.
完美使用
python 多进程模块提供了一个JoinableQueue类,追根溯源继承于 Queue,源码看的头疼.
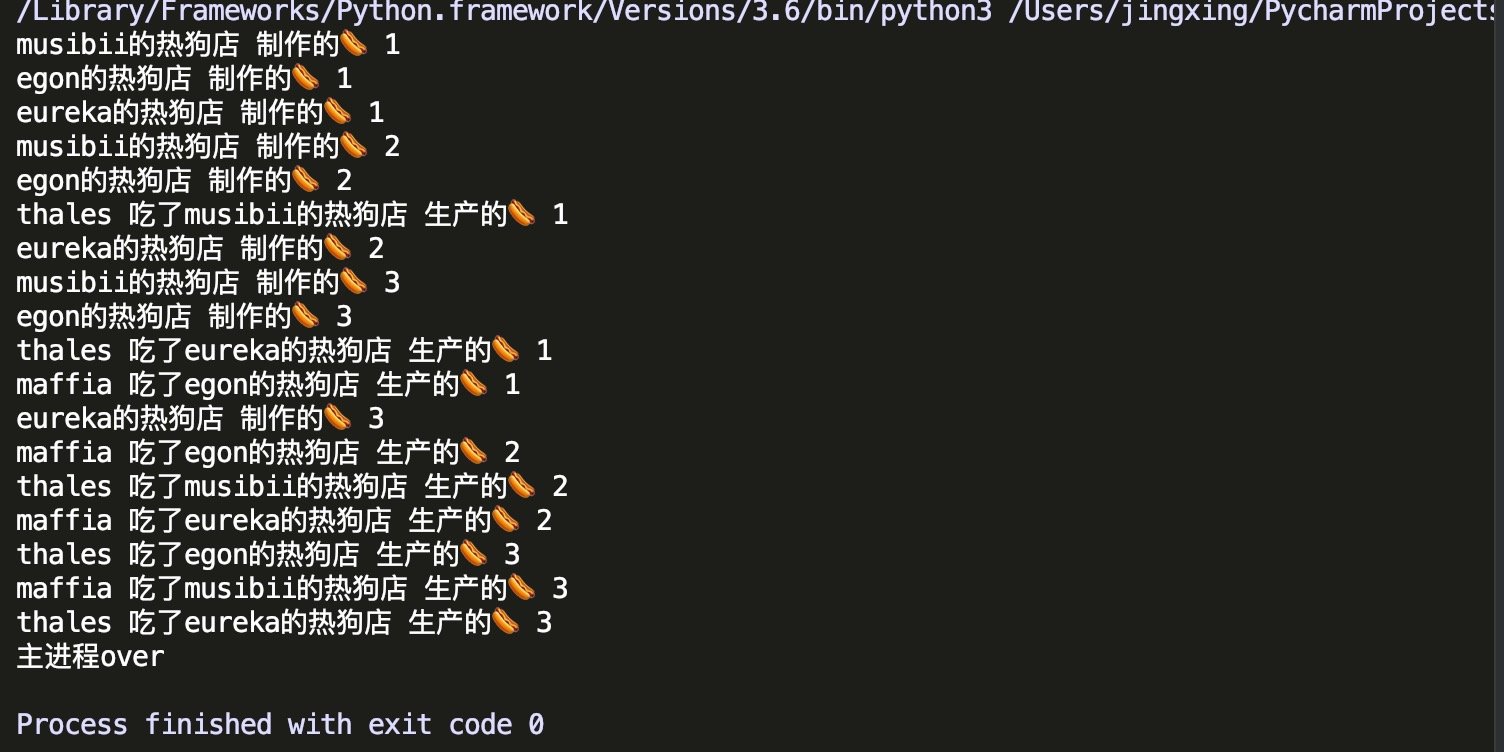
import time, randomfrom multiprocessing import Process, JoinableQueue# 制作热狗def make_hotdog(queue, name):
for i in range(1,4):
time.sleep(random.randint(1, 2))
print("%s 制作的 %s" % (name, i)) # 生产得到的数据
data = "%s 生产的 %s" % (name, i) # 存到队列中
queue.put(data) # 装入一个特别的数据 告诉消费方 没有了
# queue.put(None)# 吃热狗def eat_hotdog(queue, name):
while True:
data = queue.get()
time.sleep(random.randint(1, 2))
print("%s 吃了%s" % (name, data)) # 该函数就是用来记录一共给消费方多少数据了 就是get次数
queue.task_done()if __name__ == '__main__': # 创建队列
q = JoinableQueue()
p1 = Process(target=make_hotdog, args=(q, "musibii的热狗店"))
p2 = Process(target=make_hotdog, args=(q, "egon的热狗店"))
p3 = Process(target=make_hotdog, args=(q, "eureka的热狗店"))
c1 = Process(target=eat_hotdog, args=(q, "thales"))
c2 = Process(target=eat_hotdog, args=(q, "maffia"))
p1.start()
p2.start()
p3.start() # 将消费者作为主进程的守护进程
c1.daemon = True
c2.daemon = True
c1.start()
c2.start() # 让主进程等三家店全都做完后....
p1.join()
p2.join()
p3.join() # 如何知道生产方生产完了 并且 消费方也吃完了
# 方法一:等待做有店都做完热狗在放None
# # 添加结束标志 注意这种方法有几个消费者就加几个None 不太合适 不清楚将来有多少消费者
# q.put(None)
# q.put(None)
# 主进程等到队列结束时再继续 那队列什么时候算结束? 生产者已经生产完了 并且消费者把数据全取完了
q.join() # 已经明确生产放一共有多少数据
# 现在 需要知道什么时候做完热狗了 生产者不知道 消费者也不知道
# 只有队列知道
print("主进程over") # 生产方不生产了 然而消费方不知道 所以一直等待 get函数阻塞
# 三家店都放了一个空表示没热狗了 但是消费者只有两个 他们只要看见None 就认为没有了
# 于是进程也就结束了 造成一些数据没有被处理运行结果:
查看 JoinableQueue 类方法 task_done 源码:
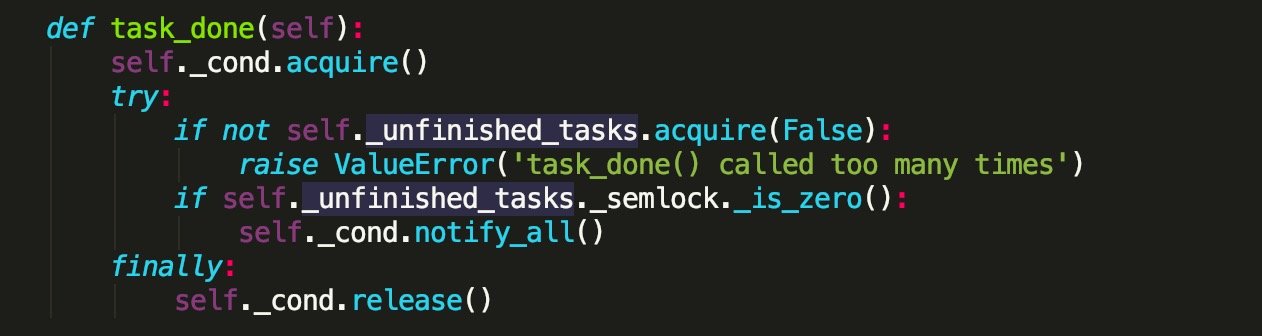
看不懂.........
共同学习,写下你的评论
评论加载中...
作者其他优质文章


