
实战机器学习,实现对房价的评估预测
前言
我们要做的是自己动手,爬取58同城上的租房网站信息,然后用该数据预测未知的房源价格。
源码涉及到三个部分,机器学习,web前端和爬虫。
预测主要是使用回归预测,预测结果比较简单,通过这个项目来简单地学习一下基于Python的回归预测。
在本文中,实现了三种回归预测算法:
1. 支持向量回归(SVR)
2. logistic回归
3. 以及使用核技巧的岭回归(L2回归)
实现过程
项目的完整代码上传到github中,该部分的实现在这里:
https://github.com/TomorrowIsBetter/crawler/tree/master/price_prediction
这个目录中的index.csv 文件就是爬出到的部分文件数据。我们可以直接来看下文件的格式:
_id,date,areas,square,methods,price,direction,type,houseAreas
http://cc.58.com/zufang/34009015301200x.shtml,1.53E+12,0,190,1,20000,0,4室2厅2卫,中信城(别墅)
http://cc.58.com/zufang/33977466998861x.shtml,1.53E+12,0,190,1,20000,0,4室2厅2卫,中信城(别墅)
http://cc.58.com/zufang/32214749419981x.shtml,1.53E+12,5,400,1,15000,0,4室3厅3卫,融创上城
http://cc.58.com/zufang/34129082983861x.shtml,1.53E+12,0,500,1,15000,0,5室3厅2卫,中海莱茵东郡
由于58同城在一线城市,例如北京,一般没有人在这上面租房和发布房源,数据大多数都是来源于中介。但是58在二三线城市的可用性还是不错的,所以这里面数据抓取的是国内某二三线城市中的数据。
模型训练
算法是统计学习方法,使用基于Python语言的scikit-learn库来实现。部分代码如下:
def normalization(data,tag=""):
mean = data.mean()
maximum = data.max()
minimum = data.min()
print(tag,mean,maximum,minimum)
return (data - mean) / (maximum - minimum)
df = pandas.read_csv("index.csv")
df = shuffle(df)
df = shuffle(df)
square = df['square'].values
square = normalization(square)
areas = df['areas'].values / 5
direction = df['direction'].values / 4
price = df['price'].values
#price = normalization(price)
print(areas.shape,square.shape,direction.shape)
data = np.array([areas,square,direction])
data = data.T
train_fraction = .8
train_number = int(df.shape[0] * train_fraction)
X_train = data[:train_number]
X_test = data[train_number:]
y_train = price[:train_number]
y_test = price[train_number:]
print(np.max(price))
# model
clf = GridSearchCV(SVR(kernel='rbf', gamma=0.1),{"C": [1e0, 1e1, 1e2, 1e3], "gamma": np.logspace(-2, 2, 5)},cv=5)
#clf = GridSearchCV(LogisticRegression(),{"C":[1e0,1e1,1e2,1e3],"random_state":list(range(10))},cv=5)
#clf = GridSearchCV(KernelRidge(kernel='rbf', gamma=0.1), {"alpha": [1e0, 1e1, 1e2, 1e3], "gamma": np.logspace(-2, 2, 5)},cv=5)
clf.fit(X_train,y_train)
result = clf.score(X_train,y_train)
test = clf.score(X_test,y_test)
c = clf.best_params_
y = clf.predict(X_test)
x = list(range(len(y)))
plt.subplot(2,1,1)
plt.scatter(x=x,y=y,color='r')
plt.scatter(x=x,y=y_test,color='g')
print(clf.best_params_,result,test)
deviation = y - y_test
deviation = deviation.flatten()
deviation = abs(deviation)
print(np.median(deviation))
plt.subplot(2,1,2)
plt.hist(deviation,10)
joblib.dump(clf,"model.m")
plt.show()
完整的代码在这个位置:
https://github.com/TomorrowIsBetter/crawler/blob/master/price_prediction/train.py
代码写的比较匆忙随意,编码格式尚不够规范。
模型说明
代码主要分为这么几个部分:
1. 数据预处理:载入数据,打乱数据,数据的归一化
2. 数据集拆分:将数据集拆分为训练集和验证集
3. 训练模型:自动测试最佳超参数,使用训练集训练模型
4. 数据可视化:将预测结果和偏差分布情况可视化出来
归一化
模型的归一化遵循下面的公式来实现:
https://mp.weixin.qq.com/s/A8exoL7iTDshh-6SeUu6rw
其中,类别部分是使用标号{0,1,…,N}来标记的不通类别,归一化时,直接直接除以N即可。
数据集乱序
训练数据集必须要进行打乱,防止训练数据倾斜,造成的预测结果偏差。
如果大家想观察一下效果,可以将这两句代码注释掉:
df = shuffle(df)
df = shuffle(df)
之后,大家就会直观地看到非乱序数据训练造成的模型预测结果。
数据集拆分
这使用的是交叉验证法,将数据集拆分为训练集和验证集两部分,其实对于深度学习这样数据集比较多的时候,一般拆分为训练集,测试集,验证集三部分,这里数据比较少,训练集和验证集的比例是 8:2
测试效果
如图所示,是该程序运行后的可视化图像:
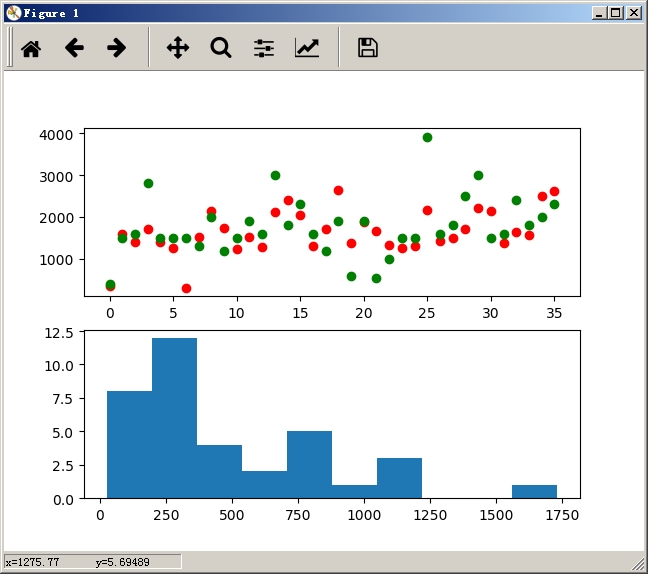
绿色是样本的实际值,红色是预测结果。从上图中可以看到,预测结果还是可以的;下面的图中显示的是预测结果与实际值之间的偏差,将该偏差以直方图的形式展现出来的。可以看到,偏差整体呈现左偏分布,主要集中在[0,500]区间范围,表明该模型达到了预测效果。
总结
github中有训练集数据和其他实现部分,大家可以参考下:
https://github.com/TomorrowIsBetter/crawler
其中,该部分内容位于price_prediction 目录中,其他部分是使用Node.js实现的爬虫以及使用AntDesign 实现的Web前端,对Web前端感兴趣的,也可以了解一下。
在这里,我们仅谈论具体的实现,对大数据,机器学习,系统架构等领域感兴趣的,可以看一下这个课程:《掌握Spark机器学习库 大数据开发技能更进一步》
这里面涉及的知识更加系统,有关机器学习,大数据方面的问题,我们将在该课程的问答环节具体探讨。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



