
前言
对于现在拥有大流量的互联网平台来说,一个微小的页面改版或者是一个微小的后台内容推荐模型参数的修改都会产生非常大的影响,如何安全的在线上流量验证这些改进是否真有助于提高公司的收益或者是用户的体验呢?
A/B Test
很容易想到做A/B Test,我们可以用一种方式把全网流量分成100份,取其中两份流量来进行实验:一份作为对照组,一份作为实验组。由于实验所占流量为全网的1%,故而影响范围小,即使出现了负收益也不影响大盘。
假设每次请求中都有req_id,我们对req_id取模,然后根据余数来划分流量。在实际工程开发中,通常会对每个实验产生一个唯一的sample_id作为试验标识,后端日志记录该sample_id的相关信息,统计组对离线日志进行统计,对一个实验下的两个sample_id(对照组sample_id,实验组sample_id)的各种统计指标进行对比,来确认试验效果。如下图所示:
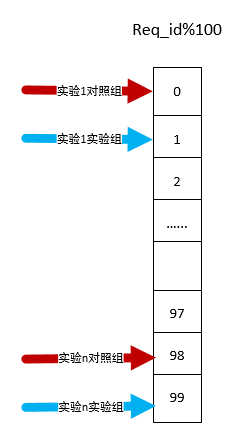
有两个实验:实验1和实验n。 每个实验又分为对照组(基线)和实验组,每组流量大小相等。 实验1对照组流量是req_id % 100 = 0,实验组是req_id % 100 = 1;实验n对照组流量是req_id % 100 = 98,实验组是req_id % 100 = 99。只要req_id最后两位分布够均匀,那么每份流量大小基本相同。
实验分层
但是这么做有一个问题,就是最多允许同时进行50个实验(每个实验占用两份流量)。在今天的互联网企业中,可能同时进行成千上万的功能开发,而每个功能背后都需要进行实验,如何尽可能同时满足这些需求呢?我们对实验进行分层:即同一份流量可能同时命中两个或者多个实验,如下图所示,一份流量可以同时命中实验1和实验n:
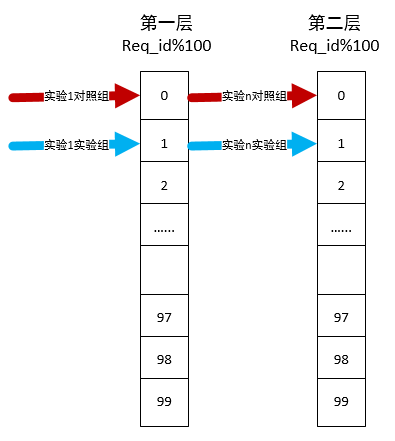
但是这么做需要有一个前提,就是两个层的实验不能互相冲突,每个层只能修改自己的参数,即如果实验1和实验n同时修改参数A,则这两个实验必须在同一层,层与层之间的划分就看层间参数是否有交集。
最终我们根据参数来划分层,有依赖关系的参数必须划分在同一层(例如页面背景颜色和字体颜色必须在同一层,如果页面背景颜色和字体颜色都被设置成蓝色,那么我们就看不到页面上的字了),没有依赖关系的参数可以划分在不同层,每个参数只出现在一个层中,不会出现在多层中。
原来每层能做50个实验,现在把参数分了n层,每层都可以同时进行50个实验,那么现在可同时进行50 * n 个实验,n为实验层数。
流量正交
但是现在还有一个问题,如上图所示实验1和实验n用的是完全相同的流量,这可能会有一些问题:我们虽然确认实验1和实验n没有参数冲突,但是无法确定实验1和实验n的实验效果是否互相影响。比如实验1进行页面改版使得页面更美观,实验n对后端推荐模型进行参数优化使得推荐内容更有趣,这两个实验不修改相同的参数所以可以分在不同的层中,但是这两个实验都会影响用户页面停留时长和用户的点击率,如果流量完全一样,我们统计的结果到底是实验1产生的影响还是实验n产生的影响呢?我们必须消除这个影响。
- 流量正交:实验1的流量必须均匀分布在后一层中,这样才能保证实验1观察的效果主要是由页面改进带来的效果,同样实验n的流量也必须均匀分布在后一层并且均匀来自于前一层。我们采用哈希值取模代替原始req_id取模,并且哈希时传入层ID,这样层与层之间的哈希值不同,从而达到均匀分布。
如下图所示:
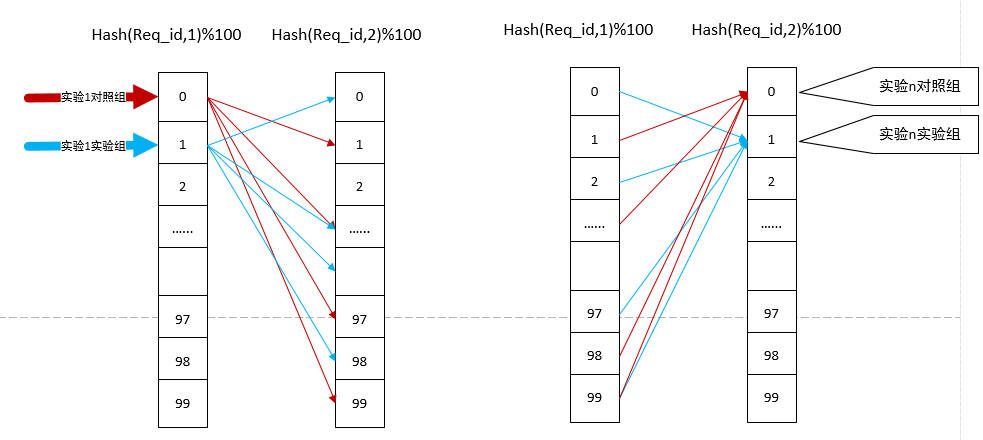
流量划分
大多时候,我们需要保持用户在产品使用上的体验一致性,例如:不能前一次看到页面字体颜色为蓝色,刷新一次页面字体变成绿色。这就提醒我们在进行流量划分的时候,不是所有实验都能够用req_id的哈希值进行划分,我们必须使用uid的哈希值进行划分,如果没有uid我们可以使用cookie的哈希值进行划分。所以,这里面有一个流量优先级划分顺序: uid > cookie > req_id。
实验转全
当我们在小流量下验证了一种改进是有效的,那么如何把这个改进在全流量上生效呢?有如两种方法。
- 直接修改代码,使其在全流量上生效。这种方式比较暴力,如果直接在全流量上修改代码使其生效,那么当遇到一些在大流量下才能发现的问题时,我们不得不重新回滚代码。
- 慢慢增大实验流量,最终使其在全流量上生效。这种方式比较稳妥,即使发生没有预料到的问题也能通过控制实验流量来止损,但是它会挤占同一层的其它实验流量,如果实验流量增大到100%,那么同一层其它实验就得不到流量。
我们针对第二种方式对试验平台进行一个改进,对每一个参数增加一个新的发射层(Launch Layer),如下图所示:
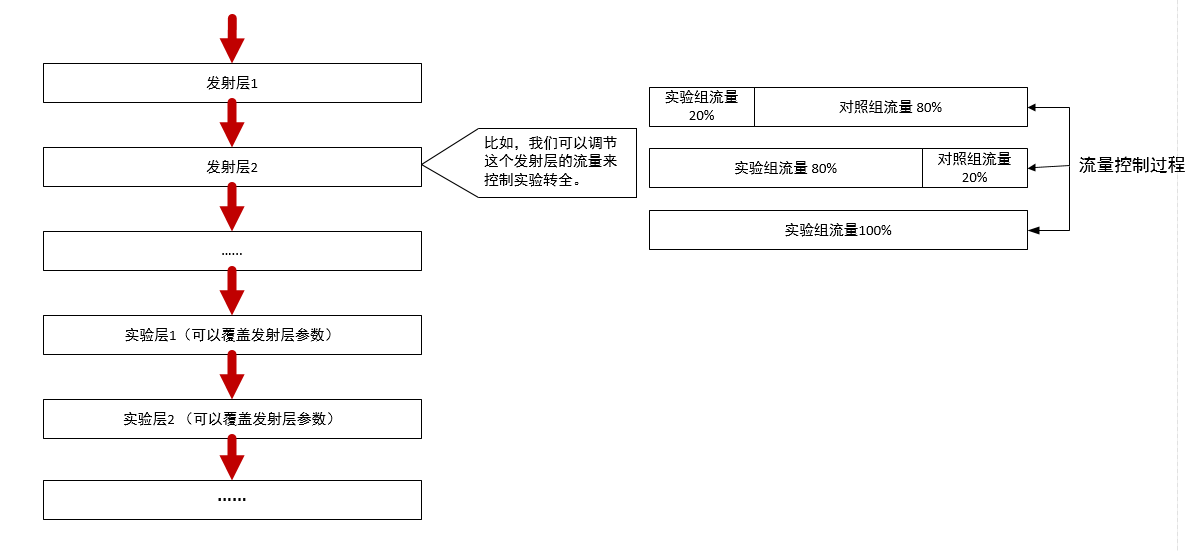
- 每个实验参数可以同时既在发射层,又在实验层。
- 实验层可以覆盖发射层的参数值。
- 每个参数最多只能在一个发射层。
当小流量实验需要全量上线时,实验进行层间转移:把实验从实验层搬到发射层,通过调节发射层的实验组与对照组(一般是基线,即线上流量用的参数默认值)比例来使得改进最终用于全流量,这样既不影响原有的实验流量分配,又能够快速调节流量大小。在调节期间,如果发现问题,可以控制发射层实验组与对照组的流量比例来止损。当我们的改进在发射层上全流量上线后,观察一段时间没有什么问题,就可以放心通过修改代码来把改进应用到线上全流量,并且撤掉发射层。
工程开发与实验评估
到此为止,我们讨论了实验平台的设计的理论依据,接下来就是工程开发。实验平台应该在一次访问的入口处,根据本次请求的相关信息来决定命中哪个实验并生成一个唯一的sample_id,之后把sample_id传递到下游服务;下游各个服务根据sample_id来人为修改代码,根据sample_id做不同的动作,并且记录相关日志。
对于一个成熟的实验平台来说,其应该具备如下几个功能:
- 能够灵活配置试验流量并快速生效(通常使用配置下发)。
- 能够检查实验配置合法性。
- 有一套信服的评估标准体系(由专门的统计组人员进行专业评估)。
结语
以上就是一个实验平台建设时需要考虑的基本的原理性的东西,希望能对小伙伴有帮助。由于水平有限,文中某些地方讲的不合理或者不对,希望小伙伴留言指教。
参考文献
《Overlapping Expeeriment Infrastructure: More, Better, Faster Experimentation》, Diane Tang, Ashish Agarwal, Deirdre O’Brien, Mike Meyer, Google, Inc.
共同学习,写下你的评论
评论加载中...
作者其他优质文章



