
二分查找有着查找速度快,平均性能好等优点,但必须要求待查表为有序表,且插入删除困难
看看JDK二分查找源码中的实现
private static int binarySearch0(int[] a, int fromIndex, int toIndex,int key) { int low = fromIndex; int high = toIndex - 1;
/* 如果改为 low < high,就有可能出现本来数组中有待查元素,却查不到的情况
比如查10,前两次查找和查12一样,最后low和high指向了元素10,
但是此时while(low<high)不成立,所以会跳出循环
*/
while (low <= high) {
//low+high可能溢出,可使用mid=low+(high-low)/2
int mid = (low + high) >>> 1;//使用位操作,效率高
int midVal = a[mid]; if (midVal < key)
low = mid + 1; else if (midVal > key)
high = mid - 1; else
return mid; // 找到目标
} return -(low + 1); // 没找到目标.
}复杂度分析
要分析时间复杂度,其实也不难,只要算出while循环了几次就行了
你要查找的数据规模如果是n,那二分一次后规模就变为n/21,二分两次后规模为n/22,...,二分m次后规模为n/2^m,若二分m次后跳出循环,则m就是循环的次数(不管查找是否成功)
最坏情况(即查不到)
假设二分m次后剩下一个元素,那么此时规模为1,同时二分m次后规模变为n/2m,则:n/2m = 1, 解出 m = lg(n),此时再循环一次,查找不到,跳出循环,所以说最多有 m+1 次循环(二分m次未跳出循环,还要二分一次),也就是查找一个元素最多需要m+1次,即lg(n)+1次比较,故二分的最坏时间复杂度为O(n) = lg(n)
折半后,要对一半元素进行遍历,复杂度是O(n),所以算法的时间复杂度为O(n * lg(n))
实战演练
题一

案例一
相邻的数不相等的性质让我们继续可以使用二分搜索来做,即使序列无序
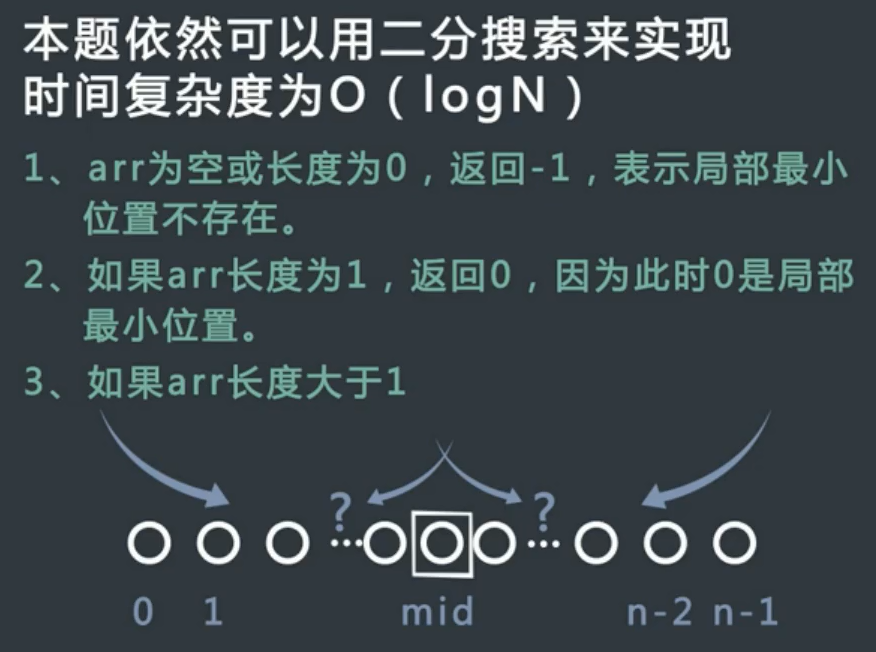
解题思路
题二

案例二

解题思路
不断二分,更新res下标
题三

案例三
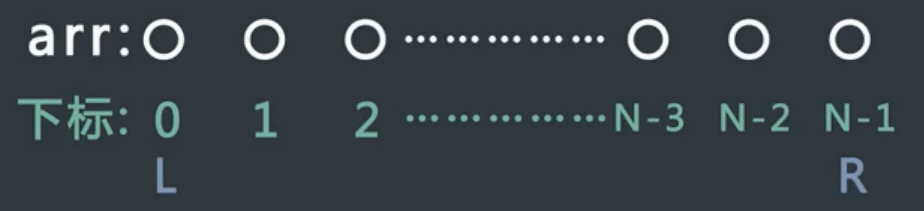
初始情况
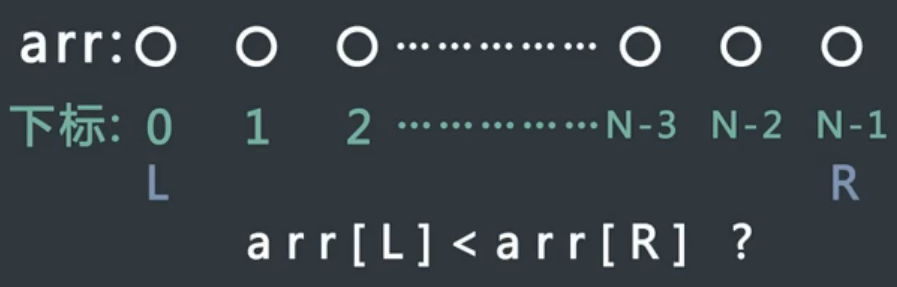
有序,直接返回

此时,就在左部分进行二分

只能遍历查找
题四

案例4

边界情况

在0-M ~1 范围内二分

M+1 - n 范围内二分
题五

案例5

图示
根的右子树的最左结点能到达最后一层,则根的左子树必为满二叉树,直接根据满二叉树计算公式求得根的左子树结点个数,再递归过程求根的右子树结点数
不能到达最后一层,说明根的右子树必为完全二叉树只不过比根的左子树少一层,此时依旧可以使用满二叉树计算公式直接求得右子树的节点个数,再加上根节点,剩下的节点则递归此过程求得根的左子树的节点数
题六

案例6

示例
作者:芥末无疆sss
链接:https://www.jianshu.com/p/86f01e1a2394
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
共同学习,写下你的评论
评论加载中...
作者其他优质文章


