
从周志华的机器学习中,我们可以得到基于信息增益准则的决策树构建算法:
输入:训练集
属性集
过程:函数的实现
1. 生成结点node;
2. if 中样本全属于同一类别 then
3. 将node标记为类叶结点;return
4. end if
5. if OR 中样本在上取值相同 then
6. 将node标记为叶结点,其类别标记为中样本数最多的类;return
7. end if
8. 从中选择最优划分属性(信息增益或者其他算法准则);
9. for 的每一个值 do
10. 为node生成一个分支;令表示中在上取值为的样本子集;
11. if 为空 then
12. 将分支结点标记为叶结点,其类别标记为中样本最多的类;return
13. else
14. 以为分支结点
15. end if
16. end for
输出:以node为根节点的一棵决策树
故,基于信息增益的决策树算法的实现代码如下:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Mon Oct 29 20:15:21 2018
@author: lxh
"""
#决策树的实现
from math import log
import time
def createDataSet():
dataSet =[[1,1,'yes'],[1,1,'yes'],[1,0,'no'],[0,1,'no'],[0,1,'no'],]
labels =['Tree','leaves']
return dataSet,labels
#计算香农熵
def calcShannonEnt(dataSet):
numEntries =len(dataSet)
labelCounts={}
for feaVec in dataSet:
currentLabel =feaVec[-1]
if currentLabel not in labelCounts:
labelCounts[currentLabel]=0
labelCounts[currentLabel]+=1
shannonEnt =0.0
for key in labelCounts:
prob =float(labelCounts[key])/numEntries
shannonEnt-=prob*log(prob,2)
return shannonEnt
#去掉已经决策过的属性
def splitDataSet(dataSet,axis,value):
retDataSet = []
for featVec in dataSet:
if featVec[axis]==value:
reducedFeatVec =featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
#根据信息增益算法,选取最优属性
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0])-1 #因为数据集的最后一项是标签
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain =0.0
bestFeature = -1
for i in range(numFeatures):
featList =[example[i] for example in dataSet]
print(featList)
uniqueVals =set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet =splitDataSet(dataSet,i,value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy +=prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy -newEntropy
if infoGain >bestInfoGain:
bestInfoGain =infoGain
bestFeature =i
return bestFeature
#因为我们递归构建决策树是根据属性的消耗进行计算的,所以可能会存在最后属性用完了,但是分类还没有算完,
#这时候就会采用多数表决的方式计算节点分类
def majorityCnt(classList):
classCount ={}
for vote in classList:
if vote not in classCount.keys():
classCount[vote] =0
classCount[vote]+=1
return max(classCount)
def createTree(dataSet,labels):
classList =[example[-1] for example in dataSet]
if classList.count(classList[0]) ==len(classList): #类别相同则停止划分
return classList[0]
if len(dataSet[0])==1:#所有特征已经用完
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel =labels[bestFeat]
myTree ={bestFeatLabel:{}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]#为了不改变原始列表的内容复制了一下
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet,bestFeat, value),subLabels)
return myTree
def main():
data,label =createDataSet()
t1 =time.clock()
myTree =createTree(data,label)
t2 =time.clock()
print(myTree)
print('execure time:',t2-t1)
if __name__=='__main__':
main()
【基于scikit-learn的决策树实现】
scikit-learn库为我们提供了实现决策树算法的接口,我们可以通过调用接口进行代码实现,本部分代码除了包含决策树代码以外,还包含:随机森林、决策树可视化、参数自动选择等代码。具体如下(jupyer):
%matplotlib inline
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.datasets.california_housing import fetch_california_housing
housing = fetch_california_housing()
print(housing.DESCR)
housing.data.shape
housing.data[0]
from sklearn import tree
dtr = tree.DecisionTreeRegressor(max_depth = 2)
dtr.fit(housing.data[:, [6, 7]], housing.target)
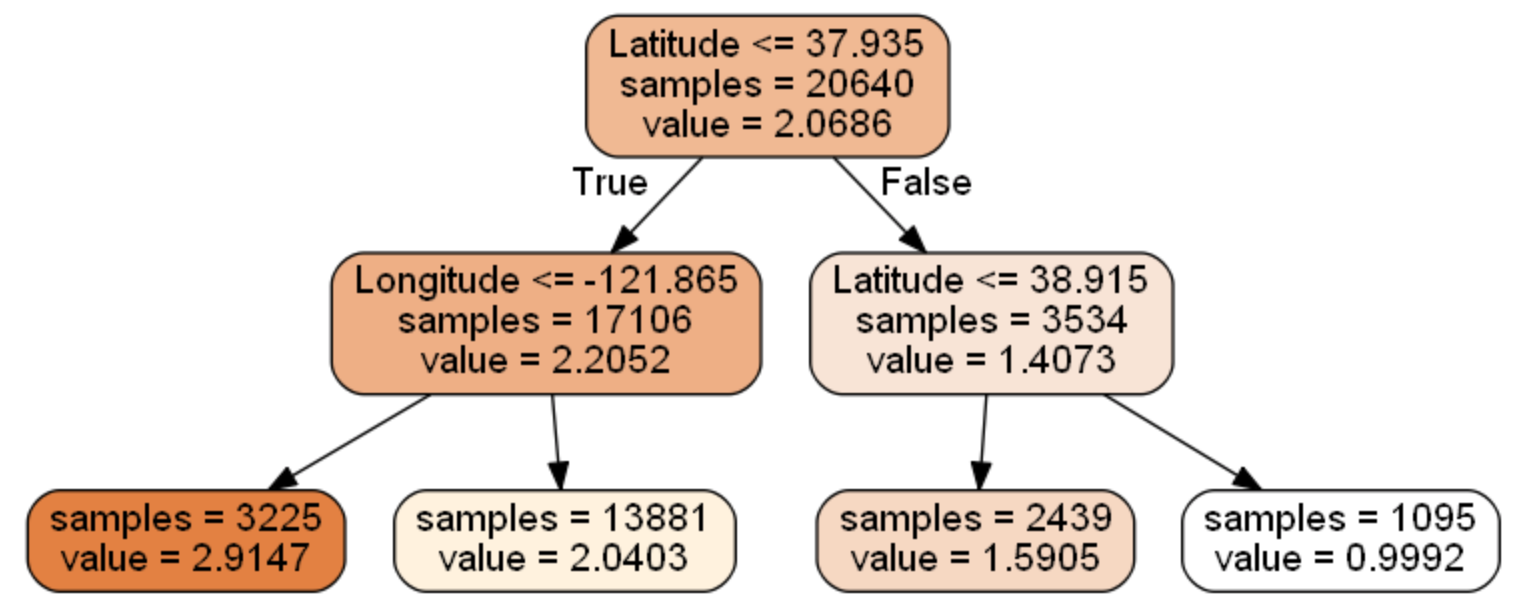
#要可视化显示 首先需要安装 graphviz http://www.graphviz.org/Download..php
dot_data = \
tree.export_graphviz(
dtr,
out_file = None,
feature_names = housing.feature_names[6:8],
filled = True,
impurity = False,
rounded = True
)
#可视化展示决策树
#pip install pydotplus
import pydotplus
graph = pydotplus.graph_from_dot_data(dot_data)
graph.get_nodes()[7].set_fillcolor("#FFF2DD")
from IPython.display import Image
Image(graph.create_png())
#保存图片
graph.write_png("dtr_white_background.png")
#随机森林算法
from sklearn.model_selection import train_test_split
data_train, data_test, target_train, target_test = \
train_test_split(housing.data, housing.target, test_size = 0.1, random_state = 42)
dtr = tree.DecisionTreeRegressor(random_state = 42)
dtr.fit(data_train, target_train)
dtr.score(data_test, target_test)
from sklearn.ensemble import RandomForestRegressor
rfr = RandomForestRegressor( random_state = 42)
rfr.fit(data_train, target_train)
rfr.score(data_test, target_test)
#参数自动化匹配
from sklearn.grid_search import GridSearchCV
tree_param_grid = { 'min_samples_split': list((3,6,9)),'n_estimators':list((10,50,100))}
grid = GridSearchCV(RandomForestRegressor(),param_grid=tree_param_grid, cv=5)
grid.fit(data_train, target_train)
grid.grid_scores_, grid.best_params_, grid.best_score_
rfr = RandomForestRegressor( min_samples_split=3,n_estimators = 100,random_state = 42)
rfr.fit(data_train, target_train)
rfr.score(data_test, target_test)
pd.Series(rfr.feature_importances_, index = housing.feature_names).sort_values(ascending = False)
决策树可视化结果如下所示:
点击查看更多内容
2人点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦