


1 Redis分布式算法原理
1.1 传统分布式算法
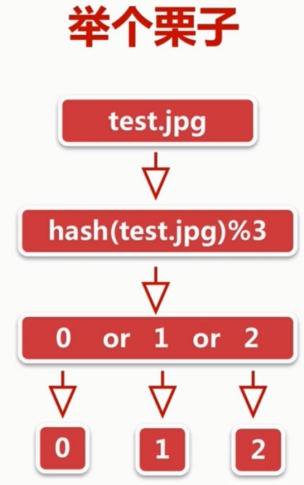
举个例子



蓝色表与4个节点时相同槽


1.2 Consistent hashing一致性算法原理
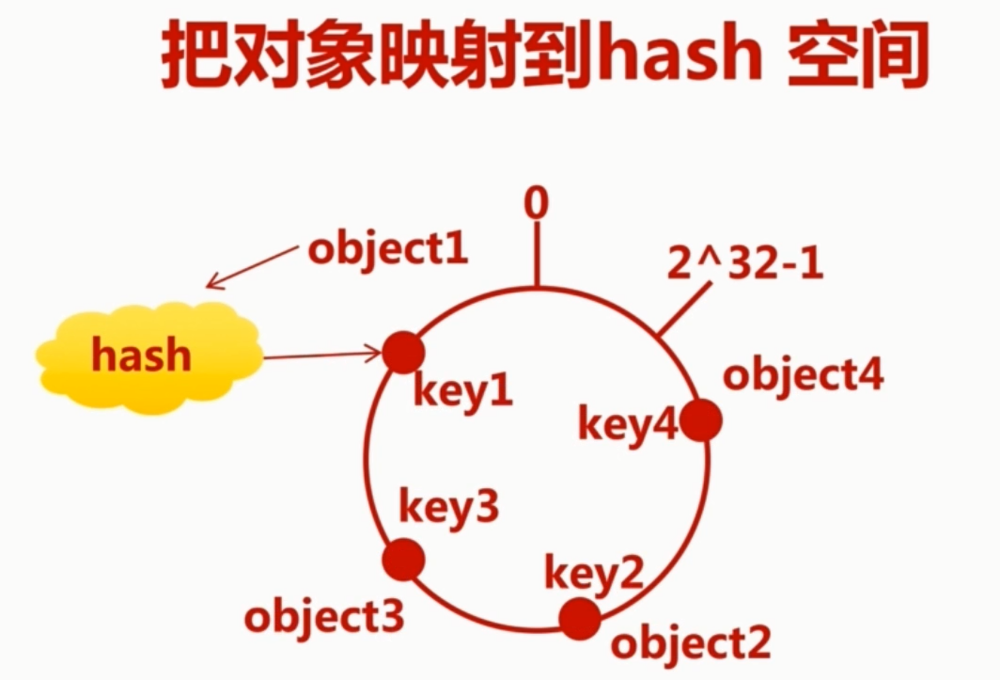
环形 hash 空间:按照常用的 hash 算法来将对应的 key 哈希到一个具有 232 个桶的空间,即(0-232-1)的数字空间中,现在我们将这些数字头尾相连,想象成一个闭合的环形
把数据通过一定的 hash 算法映射到环上
3 将机器通过一定的 hash 算法映射到环上
4节点按顺时针转动,遇到的第一个机器,就把数据放在该机器上

在移除 or 添加一个 cache 时,他能够尽可能小的改变已经存在 key 映射关系。
删除CacheB后,橙色区为被影响范围
也许心中的分布式这样的
但实际会这样拥挤-即倾斜性
1.3 ##Hash倾斜性
为解决此类事件,引入了虚拟节点服务器台数n,新增服务器数m











2 Redis分布式环境配置

3 Redis分布式服务端及客户端启动

4封装分布式Shared Redis API
4.1 SharedJedis源码解析

ShardedJedis.png
封装RedisSharedPool
测试代码
集成测试
5 Redis分布式环境验证

6 集群和分布式
分布式:不同的业务模块拆分到不同的机器上,解决高并发的问题。 工作形态
集群:同一个业务部署在多台机器上,提高系统可用性 是物理形态
集群可能运行着一个或多个分布式系统,也可能根本没有运行分布式系统;分布式系统可能运行在一个集群上,也可能运行在不属于一个集群的多台(2台也算多台)机器上。
你前台页面有10个用户,分别发送了1个请求,那么如果不是集群的话,那这10个请求需要并行在一台机器上处理,如果每个请求都是1秒钟,那么就会有一个人等待10秒钟,有一个人等待9秒钟,以此类推;那么现在在集群环境下,10个任务并分发到10台机器同时进行,那么每个人的等待时间都还是1秒钟;
当然,你说的浪费确实是,如果系统的并发不是很高,只有一台或者两台机器就能处理的话,那确实是有很大的浪费
作者:芥末无疆sss
链接:https://www.jianshu.com/p/70d3884eaba0
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
共同学习,写下你的评论
评论加载中...
作者其他优质文章


