
一 介绍
HDFS中如下组件:
1) NameNode : 存储文件的元数据,如文件名,文件目录结构,文件属性等。
2) DataNode: 在文件系统中存储文件块的数据等。
3)Secondary NameNode: 用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
二 使用HDFS并运行MapReduce程序
1 首先将 etc/hadoop/hadoop-env.sh 中的
| export JAVA_HOME=/opt/module/jdk1.8.0_144 |
JAVA_HOME改成本地jdk的路径
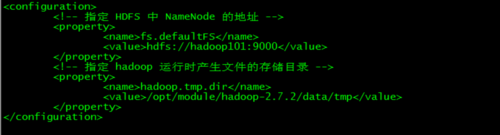
2 配置 core-site.xml
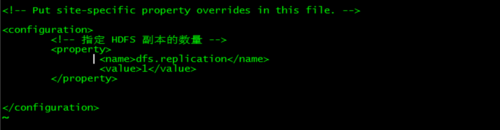
3 配置hdfs-site.xml
4 启动集群
(a) 格式化 namenode(第一次启动时格式化,以后就不要总格式化)

(b) 启动 namenode,jps查看是否启动成功

(c) 启动 datanode

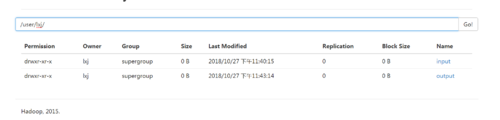
5 web查看
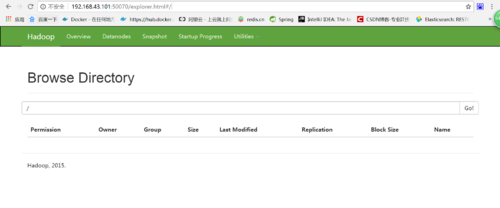
出现如图则表示已经成功搭建好文件系统
6 操作集群进行工作

在文件系统上创建目录,在web端查看
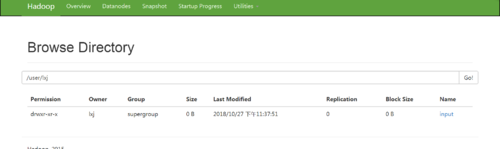
将文件上传到文件系统进行测试


运行mapreduce程序

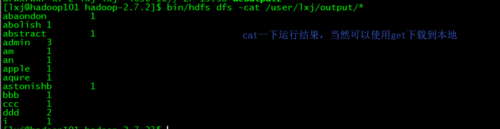
可直接点击下载文件,查看结果,也可通过命令获取到本机

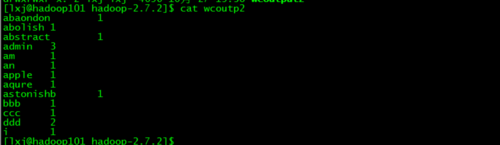
删除结果

点击查看更多内容
为 TA 点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦