
Java中的应用
java.util.Vector类中
/**
* Returns the index of the first occurrence of the specified element in
* this vector, searching forwards from {@code index}, or returns -1 if
* the element is not found.
* More formally, returns the lowest index {@code i} such that
* <tt>(i >= index && (o==null ? get(i)==null : o.equals(get(i))))</tt>,
* or -1 if there is no such index.
*
* @param o element to search for
* @param index index to start searching from
* @return the index of the first occurrence of the element in
* this vector at position {@code index} or later in the vector;
* {@code -1} if the element is not found.
* @throws IndexOutOfBoundsException if the specified index is negative
* @see Object#equals(Object)
*/
public synchronized int indexOf(Object o, int index) { if (o == null) { for (int i = index ; i < elementCount ; i++) if (elementData[i]==null) return i;
} else { for (int i = index ; i < elementCount ; i++) if (o.equals(elementData[i])) return i;
} return -1;
}举个例子,有一字符串"BBC ABCDAB ABCDABCDABDE"是否包含另一个字符串"ABCDABD"
Knuth-Morris-Pratt算法简称KMP是最常用的之一

1
字符串"BBC ABCDAB ABCDABCDABDE"的第一个字符与搜索词"ABCDABD"的第一个字符进行比较。B与A不匹配,搜索词后移一位

2
B与A不匹配,搜索词再往后移
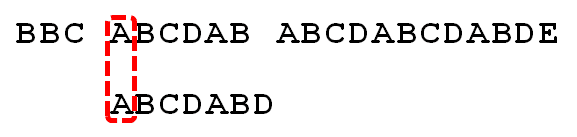
3
直到有一个字符,与搜索词的第一个字符相同
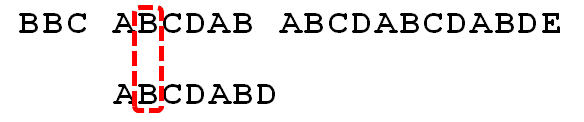
4
接着比较字符串和搜索词的下一个字符,还是相同
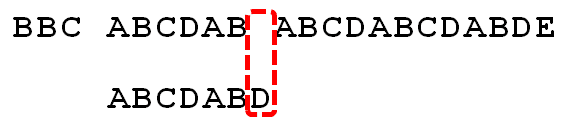
5
直到字符串有一个字符,与搜索词对应的字符不相同为止

6
这时,最直接的反应是,将搜索词整个后移一位,再从头逐个比较。
这样做虽然可行,但是效率很差,因为你要把"搜索位置"移到已经比较过的位置,重比一遍
7
一个基本事实是,当空格与D不匹配时,你其实知道前面六个字符是"ABCDAB"。
KMP算法的思想是,设法利用这个已知信息,不要把"搜索位置"移回已经比较过的位置,继续把它向后移,这样就提高了效率
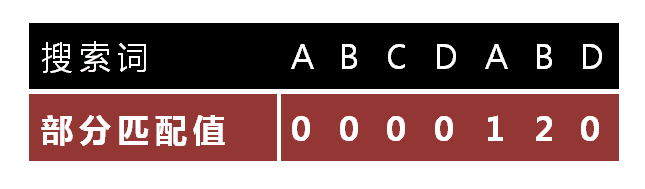
8
针对搜索词,制《部分匹配表》(制作方法后面详细解析)
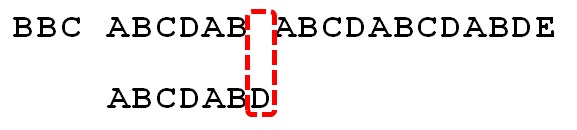
9
已知空格与D不匹配时,前面六个字符"ABCDAB"是匹配的
查表可知,最后一个匹配字符B对应的"部分匹配值"为2,因此按照下面的公式算出向后移动的位数
移动位数 = 已匹配的字符数 - 对应的部分匹配值
因为 6 - 2 等于4,所以将搜索词向后移动4位
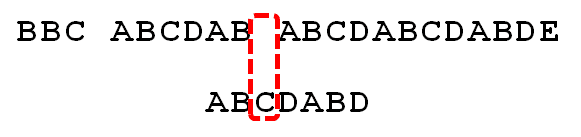
10
因为空格与C不匹配,搜索词还要继续往后移。这时,已匹配的字符数为2("AB"),对应的"部分匹配值"为0。所以,移动位数 = 2 - 0,结果为 2,于是将搜索词向后移2位。

11
因为空格与A不匹配,继续后移一位

12
逐位比较,直到发现C与D不匹配。于是,移动位数 = 6 - 2,继续将搜索词向后移动4位。

13
逐位比较,直到搜索词的最后一位,发现完全匹配,于是搜索完成。如果还要继续搜索(即找出全部匹配),移动位数 = 7 - 0,再将搜索词向后移动7位,这里就不再重复了。

14
《部分匹配表》的产生
"前缀"
除了最后一个字符以外,一个字符串的全部头部组合
"后缀"
除了第一个字符以外,一个字符串的全部尾部组合

15
"部分匹配值"就是"前缀"和"后缀"的最长的共有元素的长度。以"ABCDABD"为例,
- "A"的前缀和后缀都为空集,共有元素的长度为0;
- "AB"的前缀为[A],后缀为[B],共有元素的长度为0;
- "ABC"的前缀为[A, AB],后缀为[BC, C],共有元素的长度0;
- "ABCD"的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素的长度为0;
- "ABCDA"的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为"A",长度为1;
- "ABCDAB"的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为"AB",长度为2;
- "ABCDABD"的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的长度为0。
16

"部分匹配"的实质
有时候,字符串头部和尾部会有重复。
比如,"ABCDAB"之中有两个"AB",那么它的"部分匹配值"就是2("AB"的长度)。搜索词移动的时候,第一个"AB"向后移动4位(字符串长度-部分匹配值),就可以来到第二个"AB"的位置。
作者:芥末无疆sss
链接:https://www.jianshu.com/p/840d7ae6f0d4
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
共同学习,写下你的评论
评论加载中...
作者其他优质文章


