
下面分享下最新的Scrapy官网架构图,供各位参考。
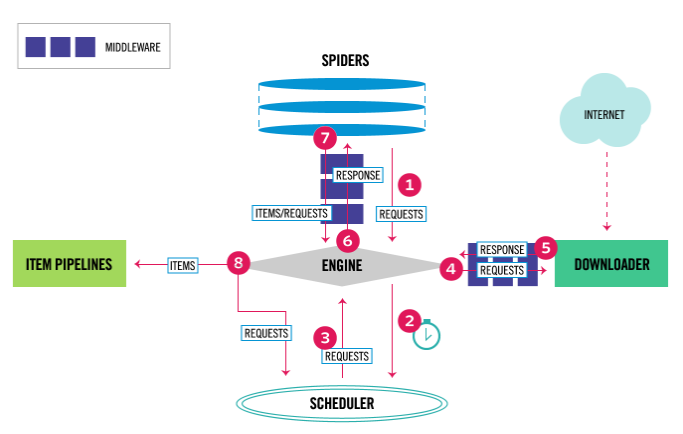
Scrapy中的数据流由执行引擎控制,如下所示:
- Engine获得从爬行器中爬行的初始请求。
- Engine在调度程序中调度请求,并请求下一次抓取请求。
- 调度程序将下一个请求返回到引擎。
- 引擎将请求发送到下载器,通过下载器中间件(请参阅process_request())。
- 页面下载完成后,下载器生成一个响应(带有该页面)并将其发送给引擎,通过下载器中间件(请参阅process_response())。
- 引擎从下载加载程序接收响应,并将其发送给Spider进行处理,并通过Spider中间件(请参阅process_spider_input())。
- Spider处理响应,并向引擎返回报废的项和新请求(要跟踪的),通过Spider中间件(请参阅process_spider_output())。
- 引擎将已处理的项目发送到项目管道,然后将已处理的请求发送到调度程序,并请求可能的下一个请求进行抓取。
- 这个过程重复(从第1步),直到调度程序不再发出请求。
Scrapy各组件介绍:
Scrapy引擎
引擎负责控制系统所有组件之间的数据流,并在某些操作发生时触发事件。
调度器 Scheduler
调度器接收来自引擎的请求,并对它们进行排队,以便在引擎请求它们时,将它们提供出来(也提供给引擎)。
下载器Downloader
下载器负责获取web页面并将其提供给引擎,而引擎又将这些页面提供给Spider。
spider
spider是由Scrapy用户编写的自定义类,用于解析响应并从其中提取项或其他请求。
Item Pipeline
Item Pipeline负责处理被Spider提取(或刮除)的条目。典型的任务包括清理、验证和持久性(比如将项目存储在数据库中)。
下载中间件)Downloader middlewares
Downloader中间件是位于引擎和下载器之间的特定钩子,当它们从引擎传递到下载器时,处理请求,以及从下载器传递到引擎的响应。
如果您需要执行以下操作之一,请使用下载器中间件:
- 在将请求发送到Downloader之前处理请求(即在Scrapy将请求发送到网站之前);
- 更改在传递给Spider之前收到响应;
- 发送一个新的请求,而不是将接收到的响应传递给爬行器;
- 将响应传递给Spider,而不获取web页面;
- 静静地丢掉一些请求。
spider中间件)Spider middlewares
Spider中间件是位于引擎和Spider之间的特定钩子,能够处理Spider输入(响应)和输出(项和请求)。
使用Spider中间件场景:
- Spider回调的后处理输出-更改/添加/删除请求或项;
- 后处理start_requests;
- 处理Spider异常;
- 对一些基于响应内容的请求调用errback而不是回调。
事件驱动的网络
Scrapy是基于用Python写的一个流行的事件驱动网络框架Twisted编写的。因此,它使用非阻塞(即异步)代码实现并发。
点击查看更多内容
7人点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦