
互联网是一个建立在数据之上的服务行业,数据质量的好坏直接影响到企业的生存能力和竞争力。如果数据质量不佳,便容易给企业带来以下危害:
干扰运营分析,影响决策;
影响算法模型质量,导致服务不够智能化;
耗费人力,分析师、算法工程师、数据科学家因为数据质量问题推倒工作重来;
接下来将介绍数据质量的评估维度,以及基于猛犸大数据平台的提高数据质量的方法,并讲解猛犸大数据平台数据质量的具体功能。
一、数据质量评估
关于如何评估数据质量,业界有很多标准。这里主要从以下四个方面去评估:
完整性
数据的记录和信息是否完整。如字段信息是否完整、有没有因上游系统出问题而导致的数据丢失、有没有出现正常100w的数据今天却没有数据的情况等。
准确性
数据的记录是否正确。简单的如是否出现常识性错误(年龄大于200岁,收货金额为负值等),电话号码、邮箱、ip等是否符合规范,枚举值是否正确等等。复杂一点的如基于维度的统计指标有没有问题,如平均值、总和、按照枚举值group by数据分布有没有异常等。
及时性
数据产出是否及时。数仓团队加工数据需要指定几点前必须产出并交给下游业务和相关分析人员。一般决策分析师需要分析前一日的数据(T+1),如果数据隔几天才能看到,就会失去分析数据的价值。而某些业务甚至有小时级别以及实时的需求,及时性要求也就更高了。
一致性
企业数仓可能存在分支,同一份数据在不同地方需要保持一致;对于一些表的值可能参照另外一些表需要保持一致;数仓设计中需要保证一致性维度;对于表的字段类型以及值也需要保持一致(如地点写上海还是上海市,性别是f、m还是0、1标示等等)。
怎么提升数据质量
基于猛犸大数据平台,数据质量提升大体可分三步进行:
Step 1:事前定义数据的监控规则
数据质量需求
下游主动发现问题、数据产品收集、监控事后问题优化
提炼规则
梳理对应指标、确定对象(多表、单表、字段)、通过影响程度确定资产等级、质量规则制定
Step 2:事中监控和控制数据生产过程
质量监控和工作流无缝对接;
支持定时调度;
强弱规则控制ETL流程;
对脏数据进行质量清洗。
Step 3:事后分析和问题跟踪
邮件短信报警(相关问题订阅)
稽核报告查询
数据质量报告的概览、历史趋势、异常查询、数据质量表覆盖率。
问题分析
异常进行评估、严重程度、影响范围确定、问题分类。
表打分和质量趋势
表的打分、表的质量趋势、表异常数据查询、对项目外提供表质量查询。
报警问题跟踪处理
数据质量事件、故障定义、故障处理和定级。
三、猛犸数据质量
为了帮助用户解决数据质量问题,我们在借鉴网易数据资产部门dmp、Griffin、阿里数加等产品以后,围绕事前、事中、事后的业务场景设计了猛犸数据质量功能。我们在数据管理里添加了数据质量模块,主要包含稽核监控、稽核概览、规则管理,在数据开发里增加数据质量节点,无缝对接工作流调度。
1.事前提炼相关稽核监控
场景1:用户信息监控。用户信息是一个每天全量表,要每天检测用户基本信息是否正确,如电话号码是否完整,email是不是唯一,用户数量是否大于0,用户数量的波动率是不是在-20%至20%之间。如果用户的数量有问题,就要阻断下游任务。
场景2:猛犸自助分析查询记录。按天分区表要通过每天查询记录来检测系统是否存在问题,如每天查询记录是否大于0,查询时间超过1800秒的占比是否小于10%,通过Impala查询且时间超过600秒占比是否小于20%。
下面,针对这两种场景,我们简要讲解一下怎么创建监控任务。在数据质量监控中,我们要明确一个监控的负责人。一个监控会对应一个表,且一个表只能设一个监控(例如,表A是分区表,一级分区字段为pt_d,二级分区字段为pt_h,那么此时能建三个监控任务,即针对整表的,针对按天的,针对按小时的)。
Step 1:选择库表以及对应分区
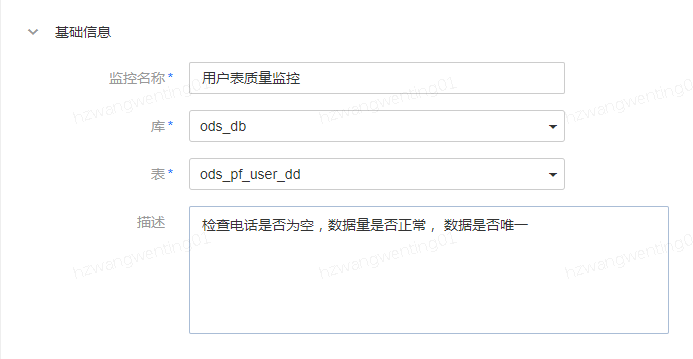
用户表监控:
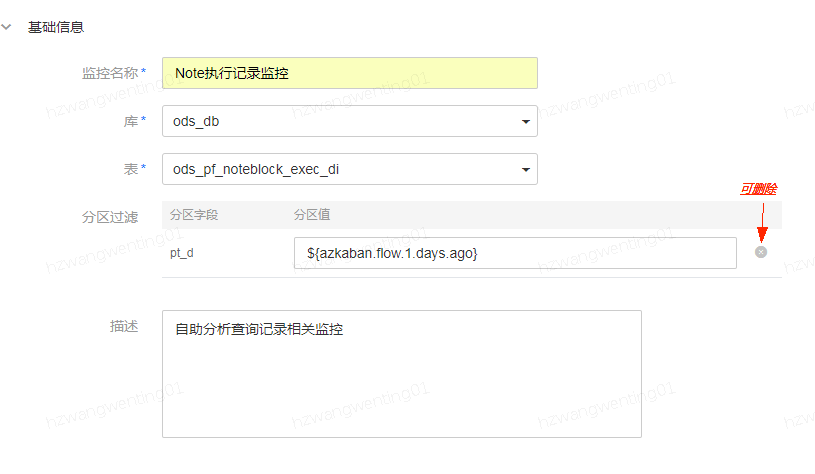
自助分析查询记录表监控:如果希望每天进行全表监控,那么可以删除pt_d分区;
Step 2:新建字段规则和表规则
字段规则:字段规则创建主要包括规则模板创建和自定义创建两种方式。
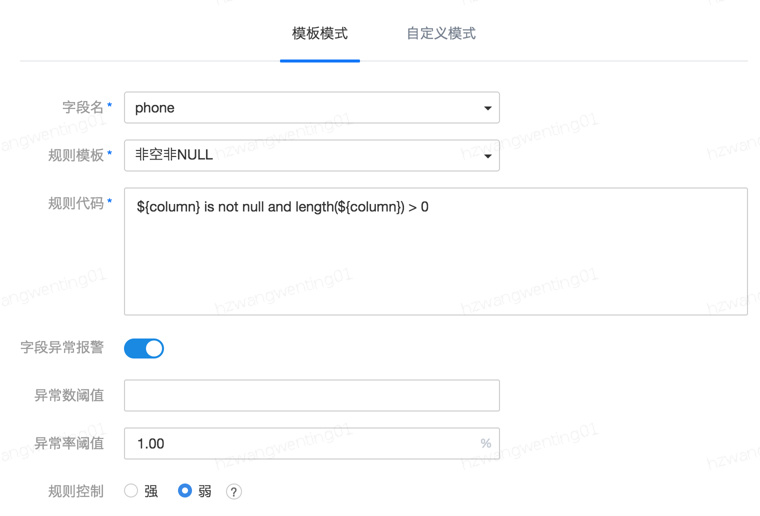
(1)规则模板创建
针对固定一个字段选取规则模板,如系统自带的非空检测、非空非NULL、IP校验等固定模板,用户也可以在规则模板管理里添加自己的模板。
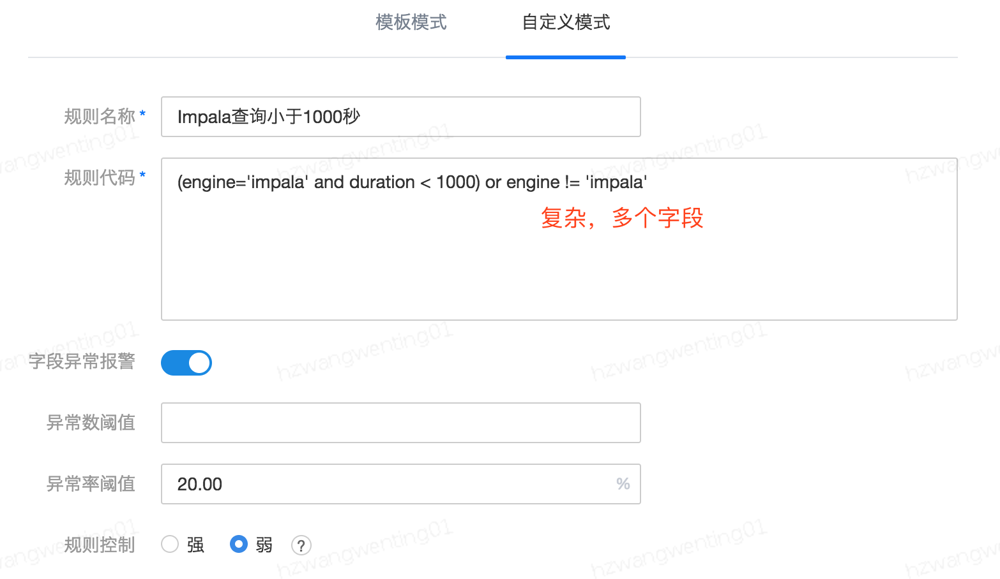
(2) 自定义创建
主要针对复杂场景,多个字段。
定义完规则后我们要触发报警,以及阻断下游任务。此时我们需要设置字段异常报警,字段异常报警主要包括异常数阈值、异常率阈值、规则控制。
异常数阈值:当表的行数或分区行数 - 规则代码匹配行数(正确行数)> 异常阈值时报警;
异常率阈值:异常行数/表的行数或分区行数 > 异常率阈值时报警;
规则控制:主要分强弱规则,当报警时如果是强规则会阻断下游任务、弱规则不阻断。
表规则
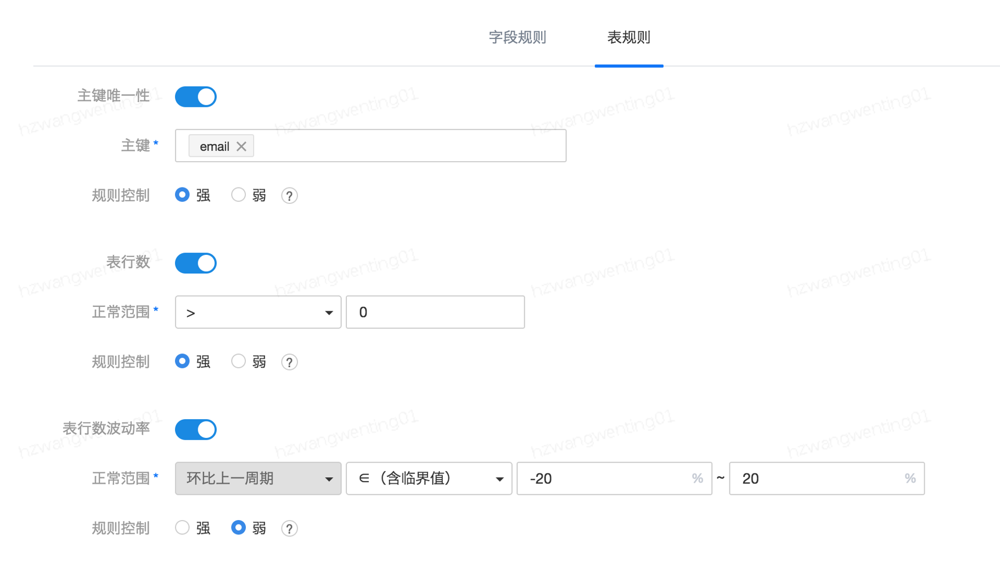
表规则主要包含三个规则:主键一致性、表行数、表的波动性
主键一致性类似如数据库里的唯一索引,可以选取多个字段。
表的波动性目前只支持环比上一周期,后面会支持昨天、月平均等等。
2.事中
在数据开发工作流里面添加数据质量节点,引用对应的质量监控任务:
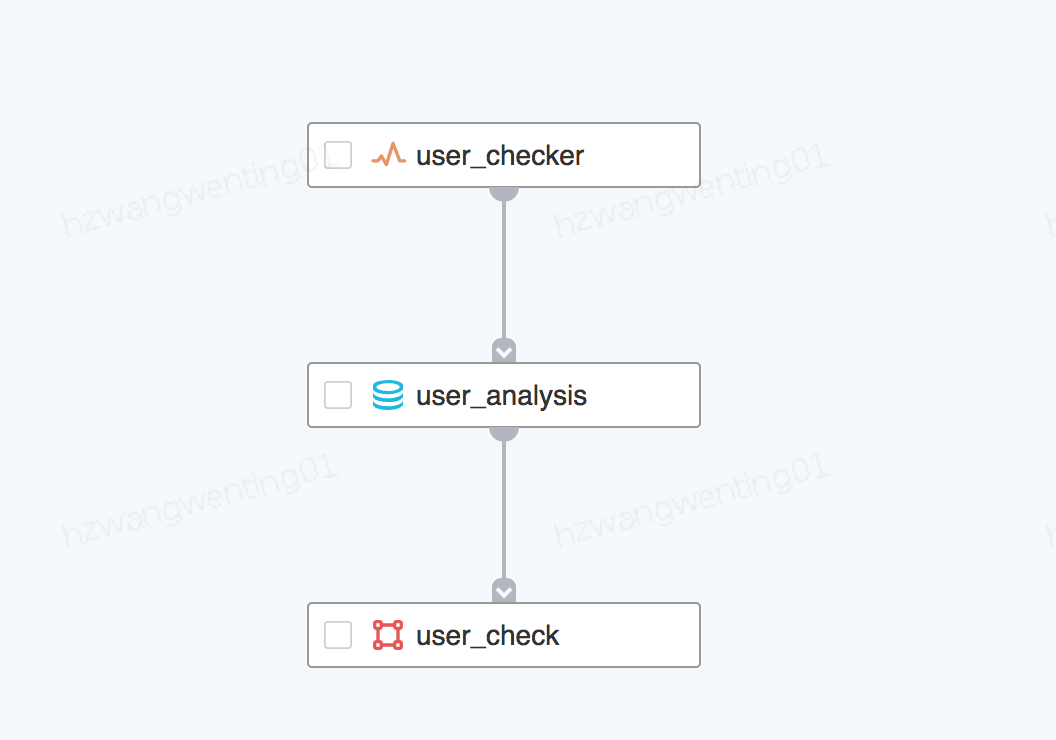
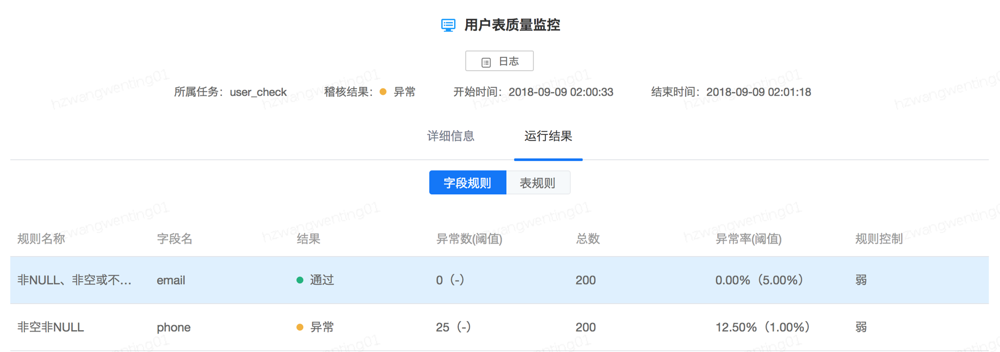
开发环境运行调试,运行结果信息和线上调度隔离;
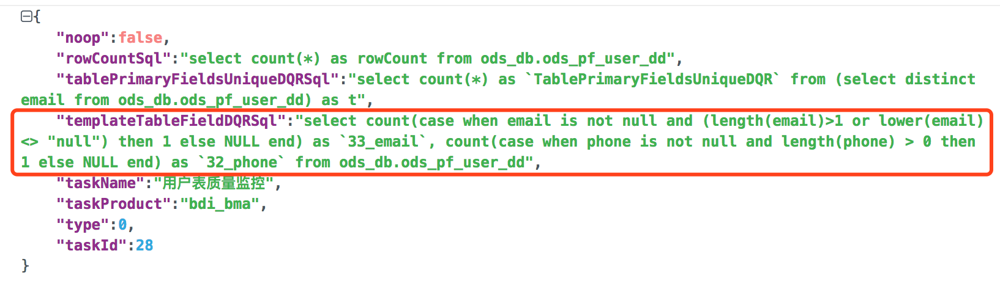
采用spark sql执行,多个字段规则一个语句执行;
设置调度上线;
针对监控异常,异常处理后进行重跑;
对于历史数据,通过补数据方式进行补跑。
3.事后
(1)稽核概览
通过开始运行时间和监控名称或表进行筛选数据质量运行情况:
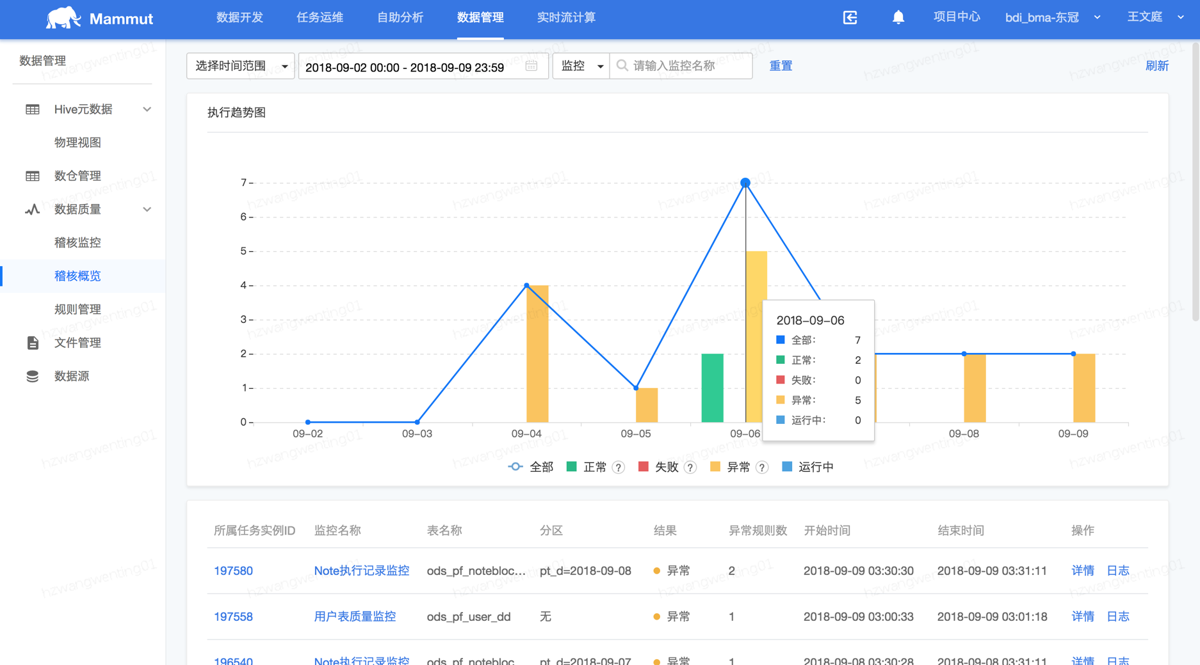
正常代表数据质量节点运行成功且监控指标正常;
失败代表数据质量节点运行失败;
异常代表数据质量节点运行成功但监控指标异常;
运行中代表数据质量节点在运行中。
(2)监控任务的执行历史查看
表规则监控
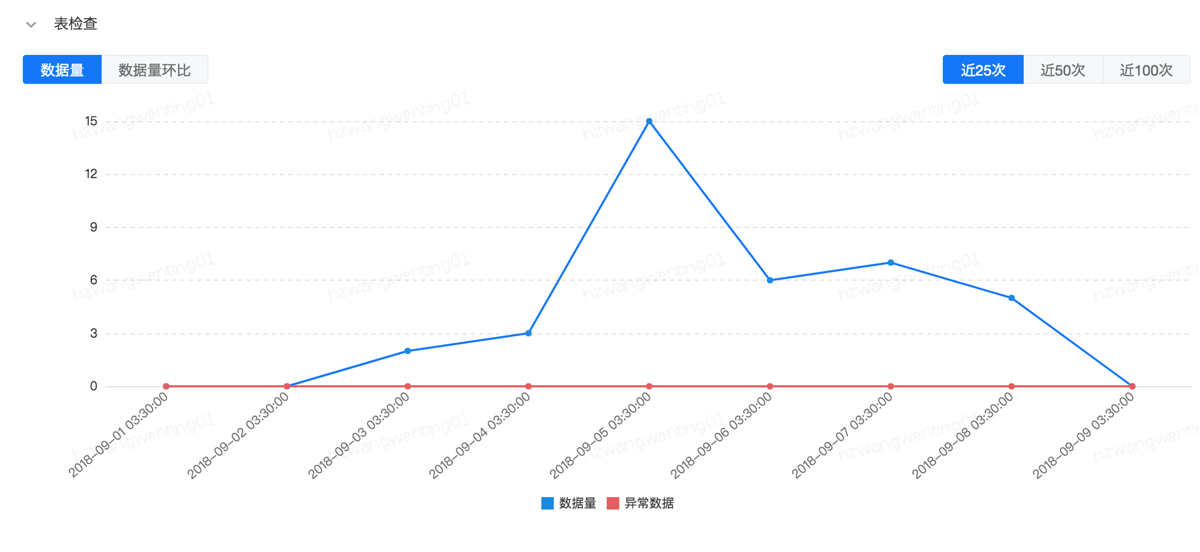
数据量代表表或者分区数据量,异常数据代表非一致性数据的记录,数据量环比记录了表的波动性。
字段规则监控
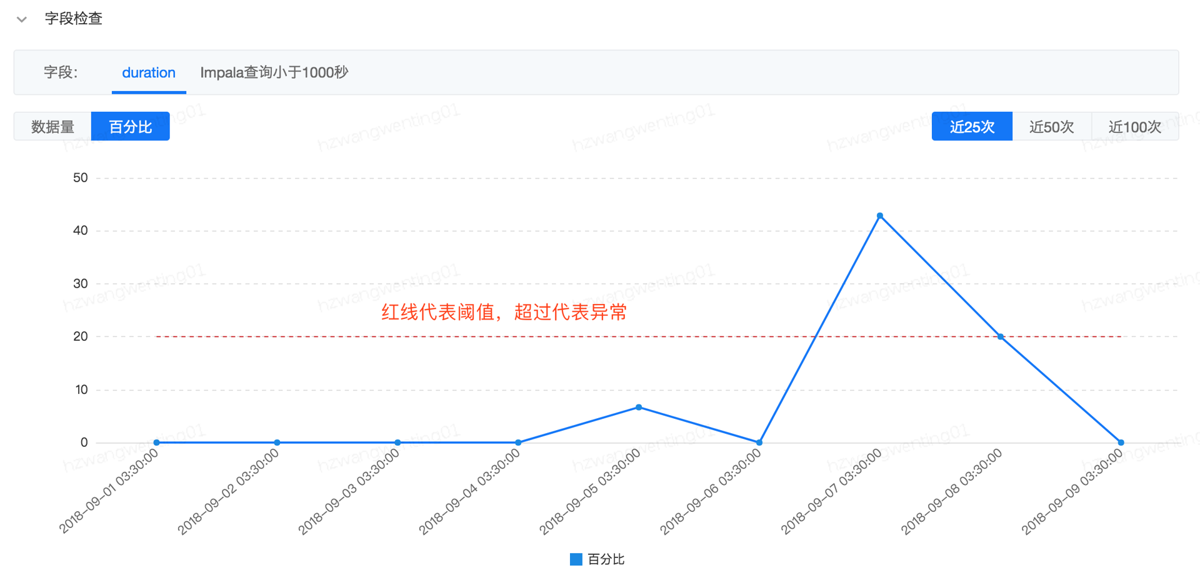
数据量记录了符合字段规则的数据,百分比记录了符合字段规则的数据占总行数的比例,红色代表异常率阈值。
4.相关注意点
一个表只能建一个监控(假设表A是分区表,一级分区字段为pt_d,二级分区字段为pt_h,那么此时能建三个监控任务,即针对整表的,针对按天的,针对按小时的)
考虑到数据质量监控任务会对应一个监控执行历史,目前一个质量监控任务只能被一个数据质量节点引用。
当表的数据量比较大的时候,可以在数据质量节点属性设置里面进行Spark相关资源设置,但目前请不要对deploy-mode进行修改
master=yarn deploy-mode=client spark-version=2.1.2 driver-memory=1024m conf.spark.dynamicAllocation.maxExecutors=4 executor-memory=2048m
默认参数
如果数据质量节点运行成功,但有强规则监控异常,节点状态将会更新成失败,如果数据质量节点运行时失败,默认影响下游节点。用户可以设置有强规则影响下游任务,也可以设置没有强规则不影响下游节点
监控任务被数据质量节点引用后,不能删除或更改选取的库表,取消引用后才能修改
表唯一健的异常数目代表有多少记录是存在多条记录。
作者:网易云社区
链接:https://www.jianshu.com/p/35ed35e7c4e6
共同学习,写下你的评论
评论加载中...
作者其他优质文章



