
大家好,我是Python进阶者。
一、前言
前几天在Python白银交流群【上海新年人】问了一个Python自动化办公实战的问题,问题如下:大佬们,我有个难度高的问题,我有个文件夹,里面呢有一堆文件,然后我要寻找至少2个关键字相同的文件,然后提取文件中第二列中的数字,第一列名称保留,譬如图片中,只要是有马桥这两个字,就分别打开这两个文件,形成新的文件,第二列的数据,依次放在B列C列这样子。
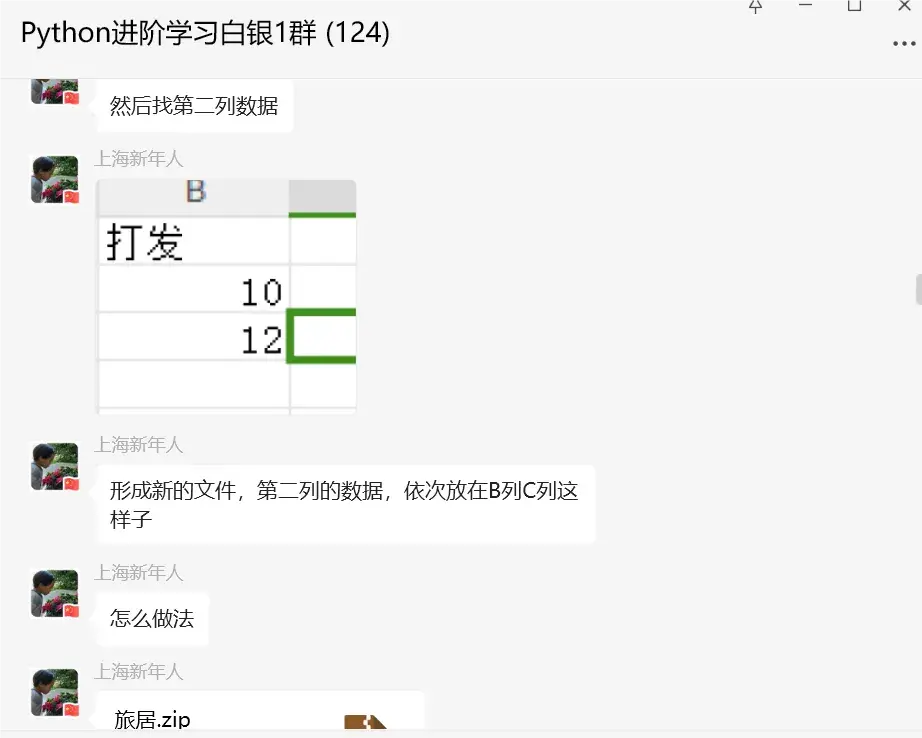
直接把问题和文件,截图等都给全盘托出了,不过咋一看,这个问题确实有点复杂,看文字确实不明所以。后来【瑜亮老师】要求他发语音补充下问题信息。
二、实现过程
这里继续补充下粉丝的需求:大哥们是这样子,就是说文件里面不是有很多文件嘛,然后呢,原先呢,等于说是他这个文件名字呢,当时取的比方说是一月份马桥,两月份马桥,三月份马桥。然后呢,我只要找到有马桥这两个字的就是文件,然后分别打开,然后呢,取第二列的那个数字。然后呢,就是新形成一个新的文件,把第二列的数字呢,放在新文件那个里面的第二列,第三列,第四列第五列,这样依次排列,这样子方便我看他这个每个月的数字的有有哪些不同。
然后呢,第一列我是保留的,因为第一列等于说里面文件当中的第一列都是相同的,然后呢,我只取要我只是我只需要提取一次就可以了,等于说第一列等于说是名字都一样的。
语音补充后确实清晰很多了,这里【瑜亮老师】给了一个具体的实现方法,具体如下所示:
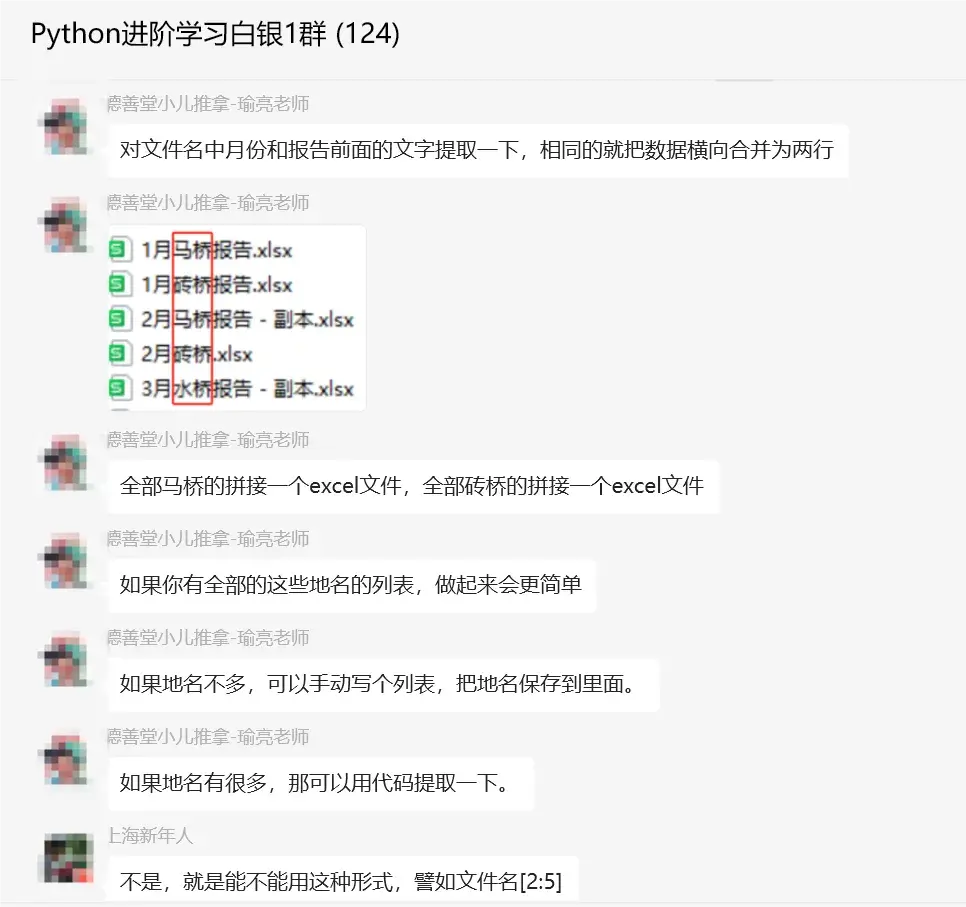
对文件名中月份和报告前面的文字提取一下,相同的就把数据横向合并为两行。全部马桥的拼接一个excel文件,全部砖桥的拼接一个excel文件,如果你有全部的这些地名的列表,做起来会更简单,如果地名不多,可以手动写个列表,把地名保存到里面。如果地名有很多,那可以用代码提取一下。
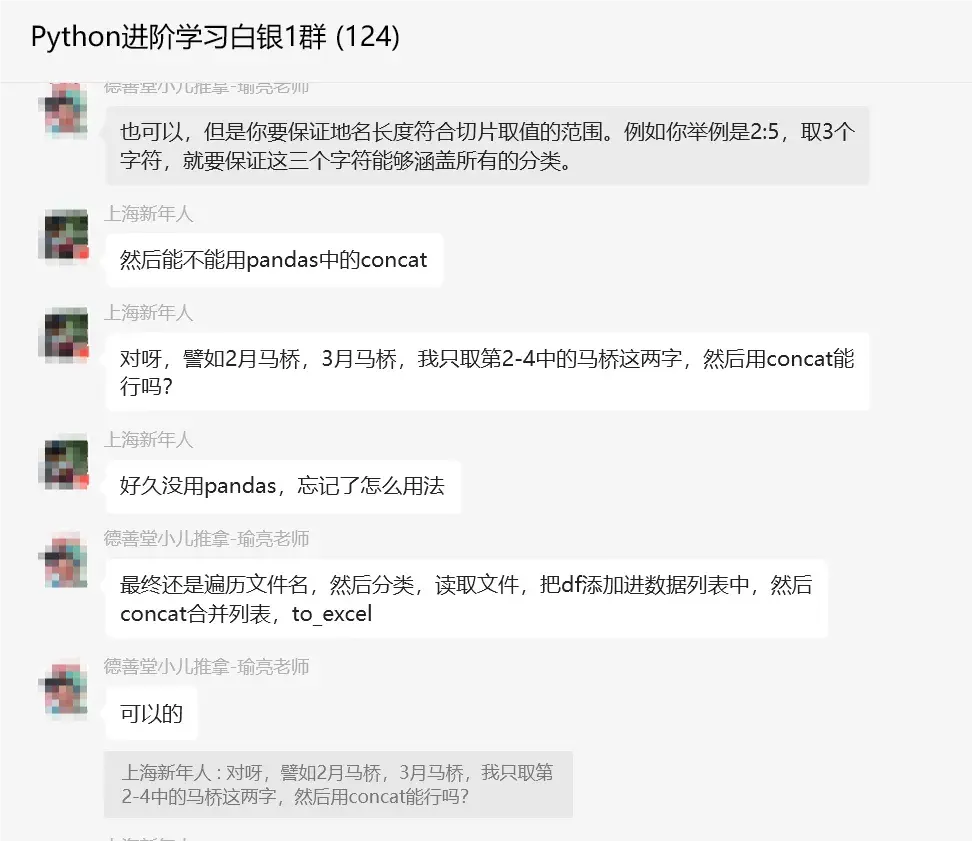
【上海新年人】:不是,就是能不能用这种形式,譬如文件名[2:5],只要是2:5完全相同就合同在一起,合并在一起,然后能不能用pandas中的concat。
【瑜亮老师】:也可以,但是你要保证地名长度符合切片取值的范围。例如你举例是2:5,取3个字符,就要保证这三个字符能够涵盖所有的分类。
【上海新年人】:对呀,譬如2月马桥,3月马桥,我只取第2-4中的马桥这两字,然后用concat能行吗?好久没用pandas,忘记了怎么用法
【瑜亮老师】:可以的。最终还是遍历文件名,然后分类,读取文件,把df添加进数据列表中,然后concat合并列表,to_excel。
【上海新年人】:用if怎么用法?每个file_name[2:4]要完全相同!
for file_name in file_names:
if file_name[2:4] = ?
【瑜亮老师】:不能这么写,存储格式最好是用{“file_name[2:4]”:[df1,df2]}这样的。
【上海新年人】:我不要这么找法!
【瑜亮老师】:具体实现如下:
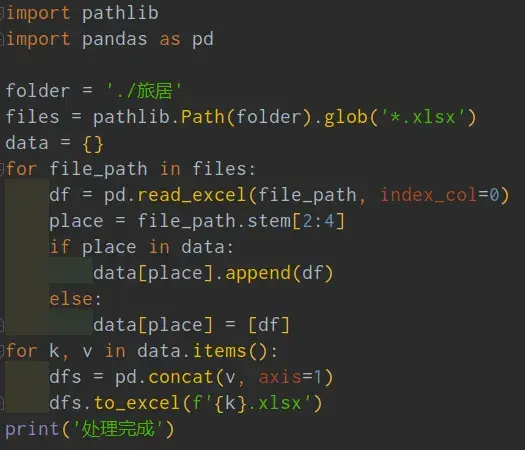
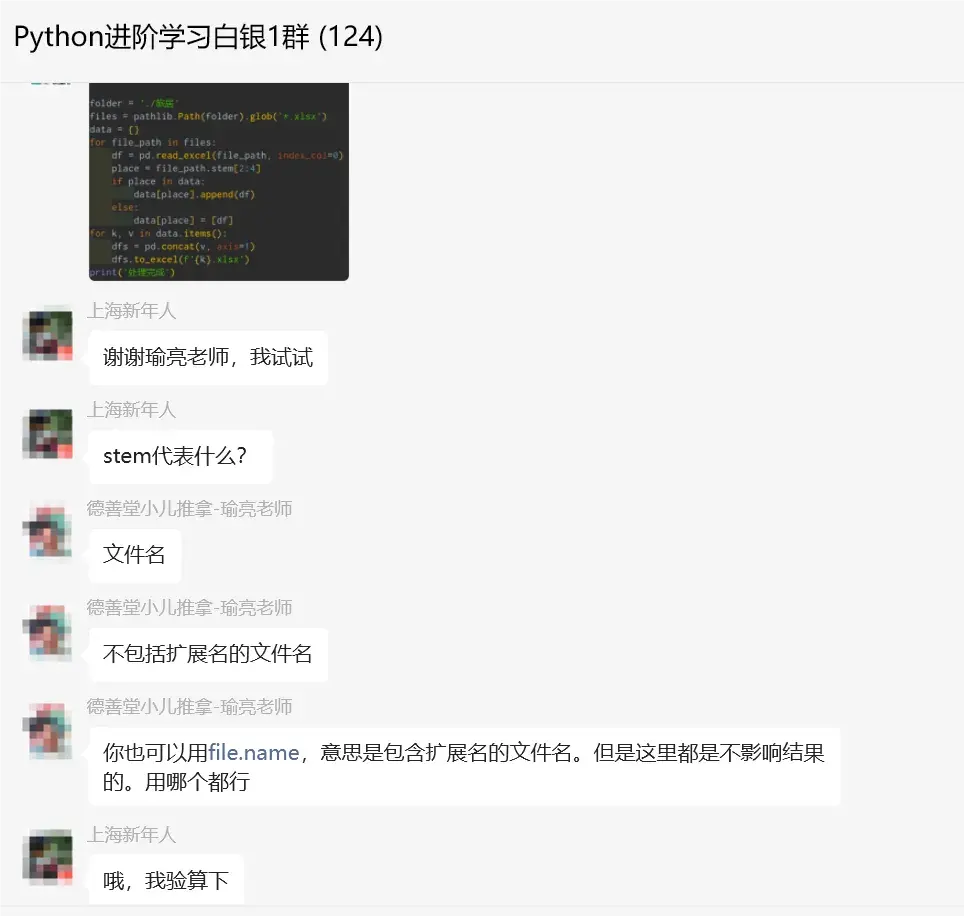
【上海新年人】:stem代表什么?
【瑜亮老师】:文件名,不包括扩展名的文件名,你也可以用file.name,意思是包含扩展名的文件名。但是这里都是不影响结果的。用哪个都行。
【上海新年人】:哦,我验算下
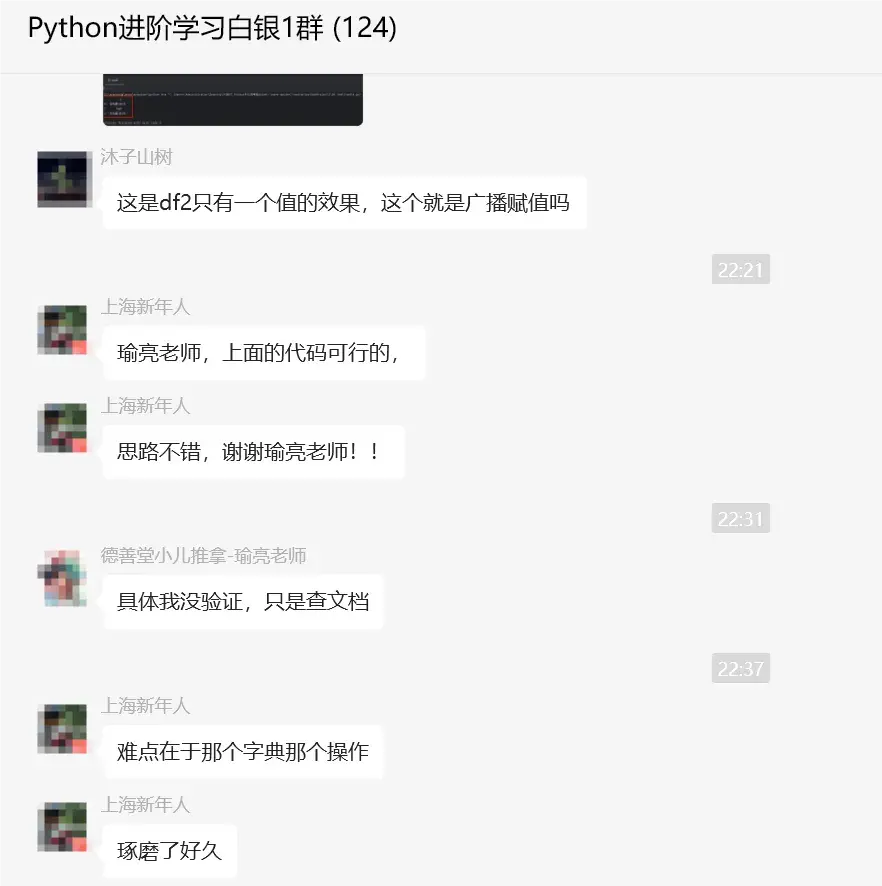
【瑜亮老师】:这里切片只取了2个字符,如果你的文件名中的地名长度超过2个字符,就会出现问题。要么数据出现混乱,要么生成的文件名不对。比如马新桥,切片只能提取出来马新。主要是数据少,只能按照你给的数据写出代码。
【上海新年人】:瑜亮老师,上面的代码可行的,思路不错,谢谢瑜亮老师!!难点在于那个字典那个操作,琢磨了好久。
顺利地解决了自己的问题。
如果你也有类似这种Python相关的小问题,欢迎随时来交流群学习交流哦,有问必答!
三、总结
大家好,我是Python进阶者。这篇文章主要盘点了一个Python自动化办公实战的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【上海新年人】提出的问题,感谢【瑜亮老师】给出的思路,感谢【莫生气】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



