
先贴一张我的论文当时查重时的截图:
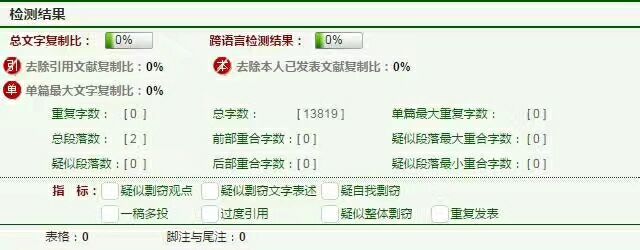
作为计算机专业的学生,毕业设计大部分都是XXX管理系统,用的技术要么是Java,要么是C#,因为这些都是已有的专业选修课。一般学生把系统做出来,演示一下,然后应对一些答辩问题,基本上都是稳稳的,不过重复率是个大问题。我印象很深的是,室友的论文重复率高达70%,这得要把论文翻译成文言文了,手动狗头。
写论文我觉得是一个思维发散再合并的过程,就像归并排序一样,先分割论文,分割到不能再分割的时候,再去合并。写毕业论文是一种艺术,不要把它当做负担。下面我来分享一下我的论文创作过程。
1、论文选题
凡事有利有弊。选择一个热门的主题,虽然实现的难度小,但是重复率不太好控制;选择一个冷门的主题,遇到的问题就是实现的难度,以及额外的学习成本,但是好处就是,不需要理解得太深。其实我不需要去担心可行性的问题,因为这些题都是导师出的。
我的选题是比较冷门的加密解密,这样大体上解决了查重问题。另外,我的论文其实没有实际的项目作为依据的,所以需要些额外的操作来扩大篇幅,比如一些数据分析,甚至数据分析的过程,都可以写在论文里。我的论文题目是:口令结构分析以及模式化破解算法。当时我觉得这个题目很高端,但时隔多年回头看看,发现里面其实没有多少深度,只不过恰好是别人不了解的领域罢了。
2、理论的描述
理论描述是极其重要的,即使你描述的内容是显而易见的,也要在论文里清除地描述出来。例如,我在我的论文开篇,详细介绍了什么是口令,口令的特点等等。这些描述看似没有任何技术含量,但是这些是论文中极其重要的一部分。做项目的不会直接介绍自己的项目,一定会去介绍自己的项目背景、项目运用到的技术等等。
回到我的论文,很显然,口令是需要自己记住的,我在这里还引用了心理学的一篇关于记忆的论文,正好我在学校也选修了心理学基础,就顺手用上去了。其实就是的“7±2效应”,大家有兴趣的话自己上网查一下。
3、数据分析的过程
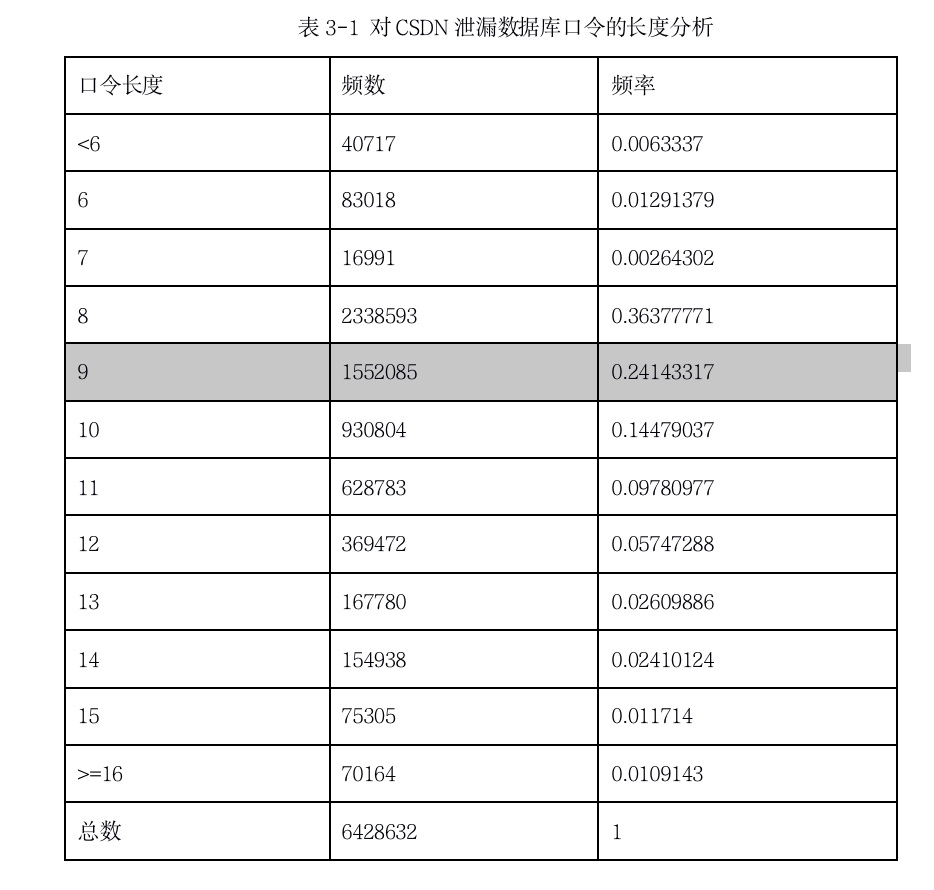
很久之前,CSND的数据库泄露,几百万用户的用户名密码都被公布到网上了。显然,这是一个不错的研究材料,我随便在网上找了找,真的找到了大约600万个CSND的数据,我还顺便简单介绍了如何将这些数据导入数据库。相比于理论描述,这波导入数据库的操作更加有技术含量。
然后,就是各种查询的操作了。我可以通过使用正则表达式来筛选出各种条件的密码,最简单的就是,我可以查出所有密码长度为9的数据一共有多少个,然后得到对应的比例。我可以把查询的SQL语句写在论文里,使得论文更加饱满。
4、切入正题
其实,上面的所有理论分析都是为后面的正题做铺垫,正题就是用一种高效的方式破解密码。准确来说,前面的铺垫也是正题的一部分。我的理论其实很简单,就是将常见的几个字符看做一个,扩大数据字典,减少密码的“位数”。举个例子,某个密码是:happy_666_qwer。我们的数据字典里,happy算是一个字,连续数字666算是一个字,键盘连续的键qwer算是一个字,那么,happy_666_qwer这个14位长度的密码,相当于5位密码,从而提升暴力破解的效率。
在我论文的理论里,类似qk,3rgE12.#p0这样杂乱无章的密码,是破解不了的,因为我认为这样的密码几乎不会出现。
5、尝试实现
其实,我并没有真正地把数据字典完整地构建出来,但我做出了一定的努力,例如,我们在把键盘连续按键加入数据字典时,就把问题转换成了求一定长度的子序列的问题。这些构建数据字典的方法,其实都可以在论文里面写出来,至少要证明这个方案是可行的。
6、暴力破解
最后考虑到答辩可能会被问到的问题,我在网上找了暴力破解加密密文的方法,就是彩虹表法。这个我试了一下,确实是可行的。然后就是稍微理解一下彩虹表法的原理,果然不出意外,答辩的时候老师确实问了这个问题。下图是破解工具的打开目录。
至此,我的毕业论文就圆满结束了。回过头来看,我的毕业论文还是环环相扣的,先从口令的概念特点出发,引入“7±2效应”,并且从600万条真实的数据,根据大多数人的记忆习惯,进一步分析出口令的特点,随后就是把用户习惯相关的数据放入数据字典里,缩短口令长度,提升破解效率。这也就是前面说的,先分再合。其实,论文每一部分拆开来看,都是很容易的,主要核心还是在于如何将这些模块组合到一起。
我还清楚地记得,论文大概一周多就解决了,而且当时我已经在外地实习了,感谢导师的远程指导。虽然我自认为这篇论文还是挺不错的,但是最终还是没有能入选优秀毕业论文。或许,我的论文只是独特而已吧。
总结——论文心得:
-
冷门选题,不一定是坏事,热门选题,不一定是好事。
-
理论与实际数据相结合,数据分析的过程很重要
-
如果大家的论文打开的内容都差不多,那么我们就去换一个打开的方式
-
提前准备好答辩可能会被问到的问题
共同学习,写下你的评论
评论加载中...
作者其他优质文章


