
MongoDB介绍
MongoDB是一个基于分布式文件存储的开源文档数据库。由C++语言编写。旨在为WEB应用提供高性能、高可用性和高伸缩数据存储解决方案。
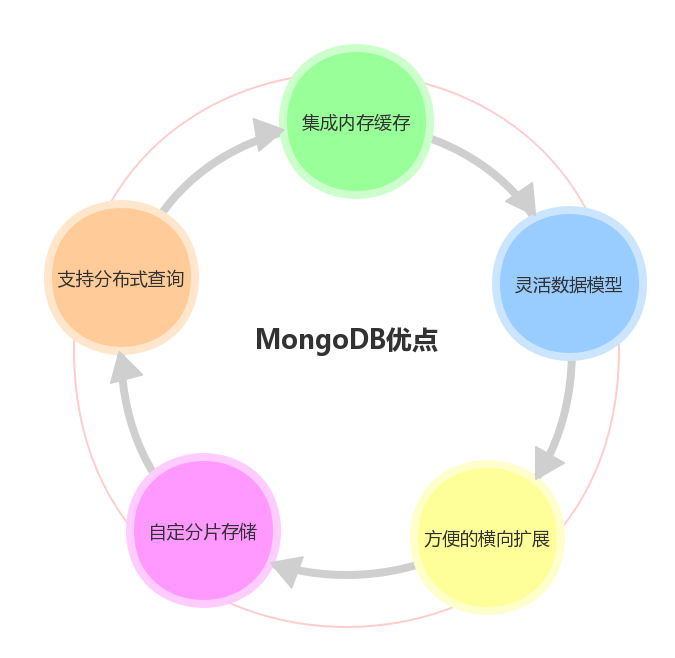
MongoDB优点
MongoDB使用场景
数据缓存
由于性能很高,MongoDB适合作为信息基础设施的缓存层。在系统重启之后,由MongoDB搭建的持久化缓存层可以避免下层的数据源过载。
对象和json存储
MongoDB的BSON(二进制JSON)数据格式非常适合文档化格式的存储及查询,而且JSON格式存储最接近真实对象模型,对开发者友好,方便快速开发迭代,灵活的模式让你不在为了不断变化的需求而去频繁修改数据库字段和结构。
高伸缩性场景
MongoDB通过分片集群,使MongoDB服务能力易于水平扩展。
弱事务类型业务
MongoDB不支持多文档事务,所以像银行系统这种需要大量原子性复杂事务的程序不适合使用MongoDB。(注:MongoDB 4.0将支持跨文档的事务)。
MongoDB概念
通过和关系型数据库mysql的对照,让我们更容易的理解MongoDB的一些概念
| 关系型数据库(sql)概念 | MongoDB概念 | 说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据行/文档 |
| column | filed | 数据字段/域 |
| index | index | 索引 |
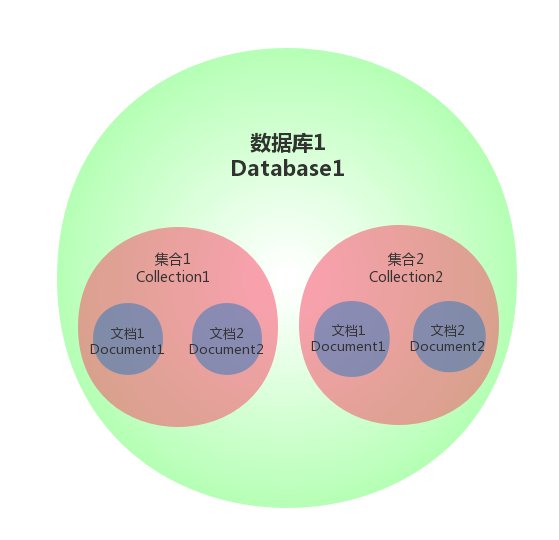
数据库
一个MongoDB中可以建立多个数据库。
MongoDB的默认数据库为"db",该数据库存储在data目录中
集合
集合名不能以"system."开头
关系型数据库中的表(table)中的每一条数据(row)的格式是事先约定好的的,而MongoDB中的集合(collection)中文档(document)的数据格式是不固定的,也就是说我们可以将如下数据插入统一文档中。
{"site":"www.wuhuan.me"}
{"site":"www.baidu.com","name":"百度"}文档
文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)
例如:在关系型数据库中有一张students表和course表,表的结构和数据如下:
students表
| id | name | sex | age |
|---|---|---|---|
| 1 | 李雷 | 0 | 12 |
| 2 | 韩梅梅 | 1 | 12 |
course表
| id | course_id | course_name | score | user_id |
|---|---|---|---|---|
| 1 | 1 | 语文 | 99 | 1 |
| 2 | 2 | 数学 | 100 | 1 |
| 3 | 1 | 语文 | 96 | 2 |
| 4 | 2 | 数学 | 98 | 3 |
以上数据和结构在MongoDB中可以使用内嵌文档来表示(一对多)的关系:
{ "_id":ObjectId("5349b4ddd2781d08c09890f3"), "name":"李雷", "sex":"0", "age":"12", "course":[{ "course_id":1, "course_name":"语文", "score":99,
},{ "course_id":2, "course_name":"数学", "score":100,
}]
}
{ "_id":ObjectId("5349b4ddd2781d08c09890f4"), "name":"韩梅梅", "sex":"1", "age":"12", "course":[{ "course_id":1, "course_name":"语文", "score":96,
},{ "course_id":2, "course_name":"数学", "score":98,
}]
}文档中的键/值对是有序的,文档中的键是不能重复,且区分大小写。
数据类型
| 数据类型 | 描述 |
|---|---|
| String | 字符串。存储数据常用的数据类型。在 MongoDB 中,UTF-8 编码的字符串才是合法的。 |
| Integer | 整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位。 |
| Boolean | 布尔值。用于存储布尔值(真/假)。 |
| Double | 双精度浮点值。用于存储浮点值。 |
| Min/Max | keys 将一个值与 BSON(二进制的 JSON)元素的最低值和最高值相对比。 |
| Array | 用于将数组或列表或多个值存储为一个键。 |
| Timestamp | 时间戳。记录文档修改或添加的具体时间。 |
| Object | 用于内嵌文档。 |
| Null | 用于创建空值。 |
| Symbol | 符号。该数据类型基本上等同于字符串类型,但不同的是,它一般用于采用特殊符号类型的语言。 |
| Date | 日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时间:创建 Date 对象,传入年月日信息。 |
| Object ID | 对象 ID。用于创建文档的 ID。 |
| Binary Data | 二进制数据。用于存储二进制数据。 |
| Code | 代码类型。用于在文档中存储 JavaScript 代码。 |
| Regular expression | 正则表达式类型。用于存储正则表达式。 |
ObjectId
MongoDB文档必须有一个默认的**_id键,且在一个集合里_id始终唯一。_id**键的值可以是任何类型的,默认是个ObjectId对象,它由MongoDB数据库自动创建。MongoDB使用objectId而不是使用常规做法(自增主键)主要原因是,在多个服务器(分布式)同步自动增加主键费力费时。
ObjectId由12个字节的BSON组成
前4个字节表示时间戳
接下来的3个字节是机器标识码
紧接的两个字节由进程id组成(PID)
最后三个字节是随机数。
创建新的ObjectId
我们可以在命令行通过如下语句来创建一个新的ObjectId
> newId=ObjectId()
上面语句将返回一个唯一的_id
ObjectId("1249b4ddd2712d08c09890f3")也可以使用生成的ObjectId替换MongoDB自动生成的ObjectId。
MongoDB基本使用
安装数据库
在windows安装MongoDB比较简单在官网MongoDB下载地址下载对应的windows安装包一键安装就行了。
安装完之后记得将MongoDB安装目录下的bin目录加入到系统的环境变量中。
启动数据库
启动数据库使用mongod命令
方式一:普通方式启动
> mongod --dbpath E:\MongoDB\data\db #不使用默认端口的话可以加上--port=[端口号]参数
E:\data\db为数据文件路径
方式二:通过配置文件启动
> mongod --config E:\MongoDB\mongo.conf
E:\MongoDB\mongo.conf为配置文件路径,配置文件内容为:
# 服务端口port=27017# 数据文件路径dbpath=E:\mongondb\data\db # 日志文件路径logpath=E:\mongondb\log\mongon.log# 打开日志输出操作logappend=true# 不使用任何的验证方式登录noauth=true
连接数据库
连接数据库使用mongo [,链接字符串]连接url的标准语法如下
mongodb://[username:password@]host[:port1][,host2[:port2],...[,hostN[:portN]]][/[database][?options]]
登录本地默认数据库服务器,无用户名密码,端口默认27017,链接默认的db数据库
> mongo mongodb://localhost/db
或者
> mongo
使用用户名admin、密码123456,登录本地端口为27017的test数据库。
> mongo mongodb://admin:123456@localhost:27017/test
创建数据库
创建数据库使用use [数据库名],例如创建一个test123的数据库
> use test123switched to db test123> dbtest123
显示当前所有的数据库可以使用命令show dbs
> show dbsdb 0.001GB local 0.000GB
怎么没有我们刚才创建的test123呢?那是因为数据库中还没有内容,我们向test123中插入db.[集合名称].insert(json格式的数据对象)一条数据,再看看!
> show dbsdb 0.001GB
local 0.000GB> use test123switched to db test123> dbtest123> db.coll.insert({"title":"not data!"})WriteResult({ "nInserted" : 1 })> show dbsdb 0.001GB
local 0.000GB
test123 0.000GB查看db.[集合名称].find()刚才添加的数据
> use test123switched to db test123> db.coll.find(){ "_id" : ObjectId("5a66e39914fea5f8ff237420"), "title" : "not data!" }使用use命令如果数据库不存在则创建,存在则切换到指定的数据库。
删除数据库
删除数据库使用db.dropDatabase()函数进行
首先查看所有的数据库
> show dbsdb 0.001GB local 0.000GB test123 0.000GB
接着切换到要删除的数据库test123
> use test123switched to db test123
删除当前数据库
> db.dropDatabase(){ "dropped" : "test123", "ok" : 1 } #删除成功数据增加
数据添加方法:insert(),insertOne(),insertMany()
添加一条数据
/** insert()方法 **/> db.person.insert({name:"张三",age:18,sex:"男"});WriteResult({ "nInserted" : 1 })> db.person.find() });{ "_id" : ObjectId("5a7941c65f6d5986321c8416"), "name" : "张三", "age" : 18, "sex" : "男" }
/** insertOne()方法插入一条数据 **/> db.person.insertOne({name:"张三",age:18,sex:"男"});{ dered:true})
"acknowledged" : true,
"insertedId" : ObjectId("5a7965855f6d5986321c8422")
}> db.person.find(){ "_id" : ObjectId("5a7965855f6d5986321c8422"), "name" : "张三", "age" : 18, "sex" : "男" }>添加多条数据
*** 方式一 把要插入的数据放在一个数组中进行批量插入***
/** insert()方法 **/> db.person.insert( [ {name:"张三",age:18,sex:"男"}, {name:"李四",age:21,sex:"女"}, {name:"王五",age:20,sex:"男"}, {name:"赵六",age:19,sex:"女"} ],{ordered:true})BulkWriteResult({
"writeErrors" : [ ],
"writeConcernErrors" : [ ],
"nInserted" : 4,
"nUpserted" : 0,
"nMatched" : 0,
"nModified" : 0,
"nRemoved" : 0,
"upserted" : [ ]
})
/** insertMany()方法 **/> db.person.insertMany( [ {name:"张三",age:18,sex:"男"}, {name:"李四",age:21,sex:"女"}, {name:"王五",age:20,sex:"男"}, {name:"赵六",age:19,sex:"女"} ],{ordered:true}){
"acknowledged" : true,
"insertedIds" : [
ObjectId("5a7969ec5f6d5986321c8430"),
ObjectId("5a7969ec5f6d5986321c8431"),
ObjectId("5a7969ec5f6d5986321c8432"),
ObjectId("5a7969ec5f6d5986321c8433")
]
}多加了一个参数{ordered:true}表示有序插入, 有序插入碰到异常时它会直接返回,不会继续插入数组中其余的文档记录。不加此参数或者{ordered:false}为无序插入, 无序的插入会在遇到异常时继续执行
*** 方式二 使用bluk对象进行数据的批量添加 ***
第一步:初始化一个批量操作对象
var bulk = db.person.initializeUnorderedBulkOp();
第二步:把要添加的数据添加到bulk对象中
bulk.insert({name:"赵六",age:19,sex:"女"});
bulk.insert({name:"赵六",age:19,sex:"女"});
bulk.insert({name:"赵六",age:19,sex:"女"});第三步:真正添加到数据库的方法
bulk.execute();
插入文档你也可以使用 db.集合名称.save(document) 命令。如果不指定 _id 字段 save() 方法类似于 insert() 方法。如果指定 _id 字段,则会更新该 _id 的数据。
insert()方法既可以插入一个数组也可插入一个对象,insertOne()方法只能插如一个对象,insertMany()只能插入一个数组,insert()返回插入成功的记录条数,而insertOne()和insertMany()方法返回成功标志和插入成功的_objectId
数据查询
查询命令:find(),findOne()
findOne()方法查询的结果已经格式化输出了,find()方法要想格式化输出数据调用pertty()修饰查询方法也能达到相同的效果。
举例:db.person.find({age:18})
查询年龄等于18的人的所有信息
举例:db.person.find({age:{$gt:18}},{name:1,sex:1})
查询db数据库中person集合中年龄大于18的人的姓名和性别
说明:如果年龄小于18可以使用$lt操作符,第二个参数{name:1,sex:1}里面表示显示的字段,如果不想显示某个字段那么就不用写如果第二个参数是{name:1},那么表示只显示姓名字段,如果整个第二个参数都不写,那么默认显示所有的字段
修饰查询的方法:limit()【限制条数】,sort()【排序】,skip()【跳过】,pretty()【美化格式】
举例:db.person.find({age:{$gt:18}},{name:1,sex:1,age:1}).sort({age:-1}).limit(3).skip(1).pretty()
查询db数据库中person集合中年龄大于18的人的姓名和性别,然后按照年龄降序排列,然后取排列后的数据的前三条,然后再跳过一条数据后的集合
说明:sort({age:-1})中的【-1】表示降序排列,如果升序排列写成sort({age:1})就可以。
数据删除
删除方法:remove(),drop()
1、remove()和drop()方法的区别
举例:db.person.remove({})
remove方法中传递一个空数对象,会删掉db数据库中的person集合中的所有的文档,但是不会删除索引
举例:db.person.drop()
会删除db数据库中的person集合中的所有的文档,并且还会删除person集合中所有的索引。效率更高。
2、删除匹配条件的文档
举例:db.person.remove({name:"张三"})
删除db数据库中person集合中name等于张三的所有文档。
3、删除一条记录
举例:
方法1 db.person.remove({name:"张三"},{justOne:true});
方法2 db.person.remove({name:"张三"},1);
只删除一个匹配条件的文档
数据修改
修改方法:update()
1、$set操作符
举例:db.person.update({name:"张三"},{$set:{age:19}})
修改名字为张三的人的年龄为19岁,只修改一条记录
2、$currentDate操作符的作用
举例:db.person.update({name:"张三"},{ $set:{age:"123456"},$currentDate: { lastModified: true }})
为当前修改的文档添加一个最后修改时间的字段
3、{multi:true}参数的作用
举例:db.person.update({name:"张三"},{$set:{age:20},$currentDate: { lastModified: true }},{multi:true})
默认情况下只修改符合条件的一个文档,如果多个文档符合条件并且都要修改只需要添加第三个参数{multi:true}就可以修改多个文档了。
4、upsert选项的作用
举例:db.person.update({name:"张三"},{name:'张三三',age:20,sex:"男"},{upsert:true})
默认情况下匹配不到更新条件的文档,update将不做任何操作,如果添加了{upsert:true}参数,在没有找到匹配文档的情况下,它将会插入一个新的文档。
注意:mongondb在修改数据的时候回根据数据的类型自动修改文档中原始的数据类型,例如一个文档中的年龄为数字类型,你修改这个记录的时候把年龄传入一个字符串,那么此文档中年龄字段的类型就变成了字符串类型。
索引
索引通常能够极大的提高查询的效率,就像书的目录一样,如果没有索引mongodb就会去扫描集合中的每个文件并选取符合查询条件的数据,在数据量大的时候这种查询相率很低下
使用db.集合名称.getIndexes()获取集合索引
> db.person.getIndexes()[
{ //person集合的默认索引
"v" : 1, //升序排列
"key" : {
"_id" : 1 //索引列
},
"name" : "_id_", //索引名称
"ns" : "test.person" //指定集合
}
]创建索引
创建索引的方法:createIndex()
举例:db.person.createIndex({"name":1})
在person集合中针对name字段创建一个升序排列的索引
> db.person.getIndexes()[
{ // 默认索引
"v" : 1,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "test.person"
},
{ //新创建的索引
"v" : 1,
"key" : {
"name" : 1
},
"name" : "name_1",
"ns" : "test.person"
}
]删除索引
删除索引使用命令:dropIndex()
举例:db.person.dropIndexes({"name":1})
> db.person.getIndexes() //查询索引[
{
"v" : 1,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "test.person"
},
{
"v" : 1,
"key" : {
"name" : 1
},
"name" : "name_1",
"ns" : "test.person"
}
]> db.person.dropIndex({"name":1}) //删除{ "nIndexesWas" : 2, "ok" : 1 }> db.person.getIndexes() //查询索引[
{
"v" : 1,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "test.person"
}
]删除全部索引使用命令:dropIndexes()
举例:db.person.dropIndexes()
> db.person.getIndexes() //查询索引[
{
"v" : 1,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "test.person"
},
{
"v" : 1,
"key" : {
"name" : 1
},
"name" : "name_1",
"ns" : "test.person"
}
]> db.person.dropIndexes() //删除全部索引{
"nIndexesWas" : 2,
"msg" : "non-_id indexes dropped for collection",
"ok" : 1
}> db.person.getIndexes() //查询索引[
{
"v" : 1,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "test.person"
}
]删除全部索引指的是:name为非_id_的索引(默认索引)
导出数据文件
mongodump -h IP --port 端口 -u 用户名 -p 密码 -d 数据库 -o 文件存在路径
如果没有用户谁,可以去掉-u和-p。
如果导出本机的数据库,可以去掉-h。
如果是默认端口,可以去掉--port。
如果想导出所有数据库,可以去掉-d。
导出全部数据数据库
mongodump -h 127.0.0.1 -o E:\mongondb\dump
导入数据文件
> mongorestore -h IP --port 端口 -u 用户名 -p 密码 -d 数据库 --drop 文件存在路径
--drop参数:先删除所有的记录,然后恢复。
导入全部数据库
> mongorestore E:\mongondb\dump #数据库的备份路径
导入test123数据库
> mongorestore -d user E:\mongondb\dump\test123 #test123这个数据库的备份路径
作者:梦想.家
链接:http://www.wuhuan.me/2018/01/22/mongodb-001/
来源:http://www.wuhuan.me
版权:https://creativecommons.org/licenses/by-nc-nd/4.0/deed.zh
共同学习,写下你的评论
评论加载中...
作者其他优质文章



